用 Python 操作 Excel 文档(基础)
Excel表格的基本结构
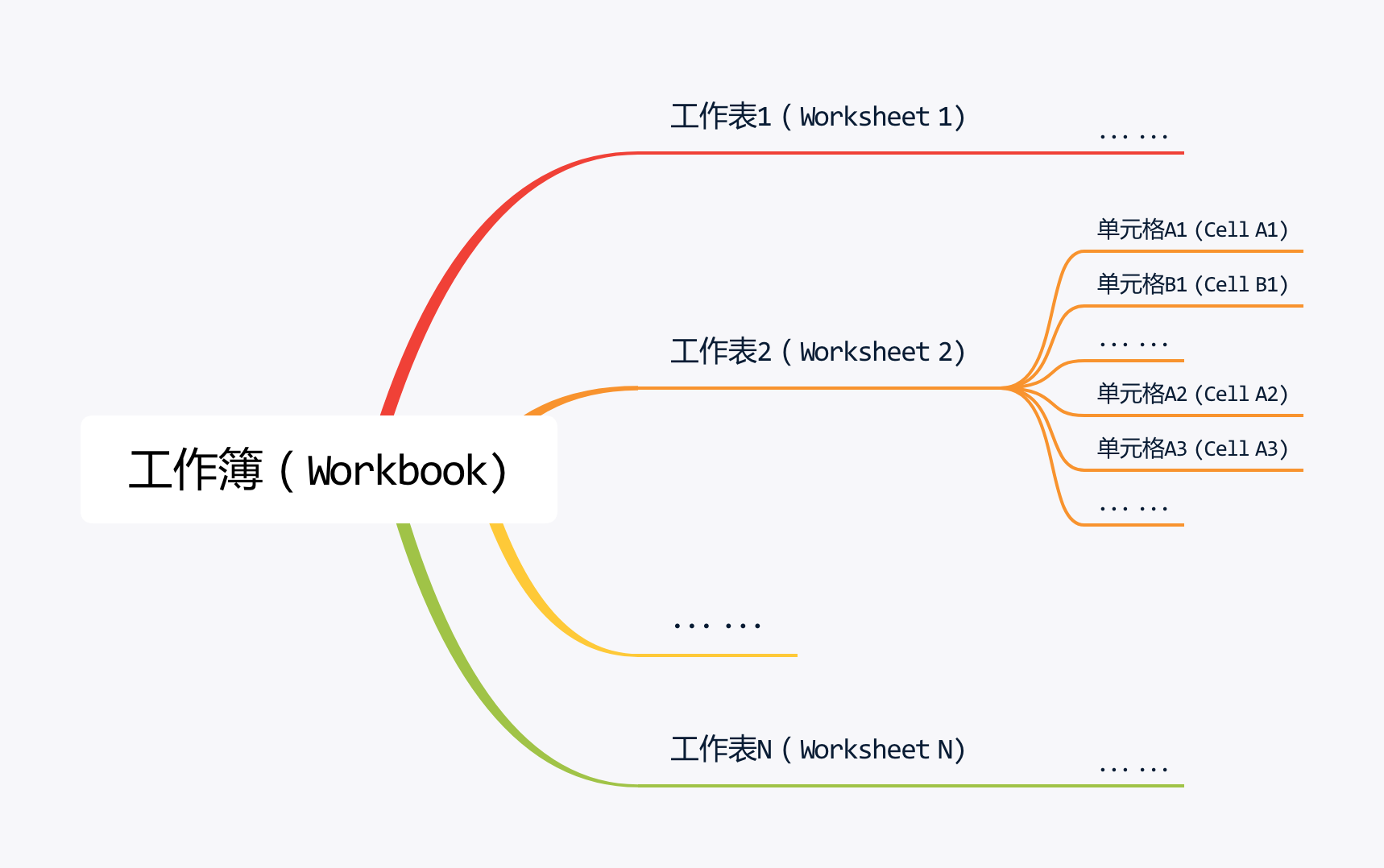
一个Excel表格文件,又叫做一个工作簿(Workbook)。
一个工作簿中包含一个或多个工作表(Worksheet)。
在工作薄页面的左下方可以进行工作表的切换和增删。
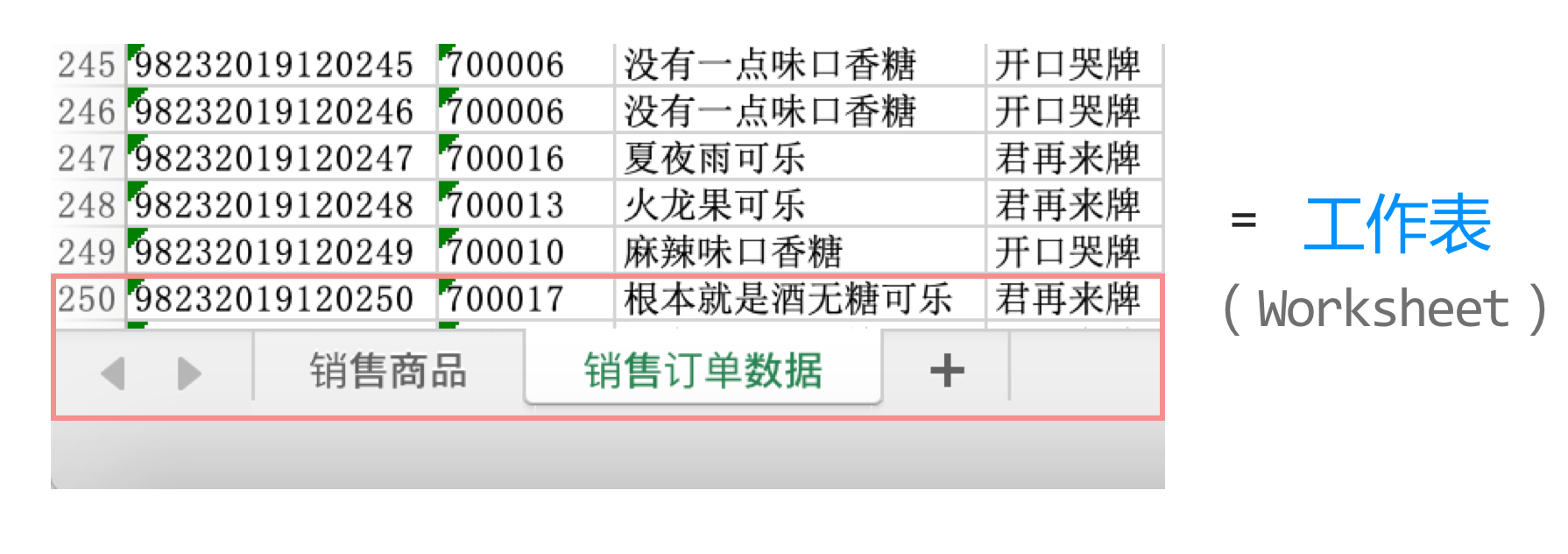
一个工作表由单元格(Cell)组成。Excel的数据存储在单元格中。
我们可以通过列号(Column)和行号(Row)对单元格进行定位。
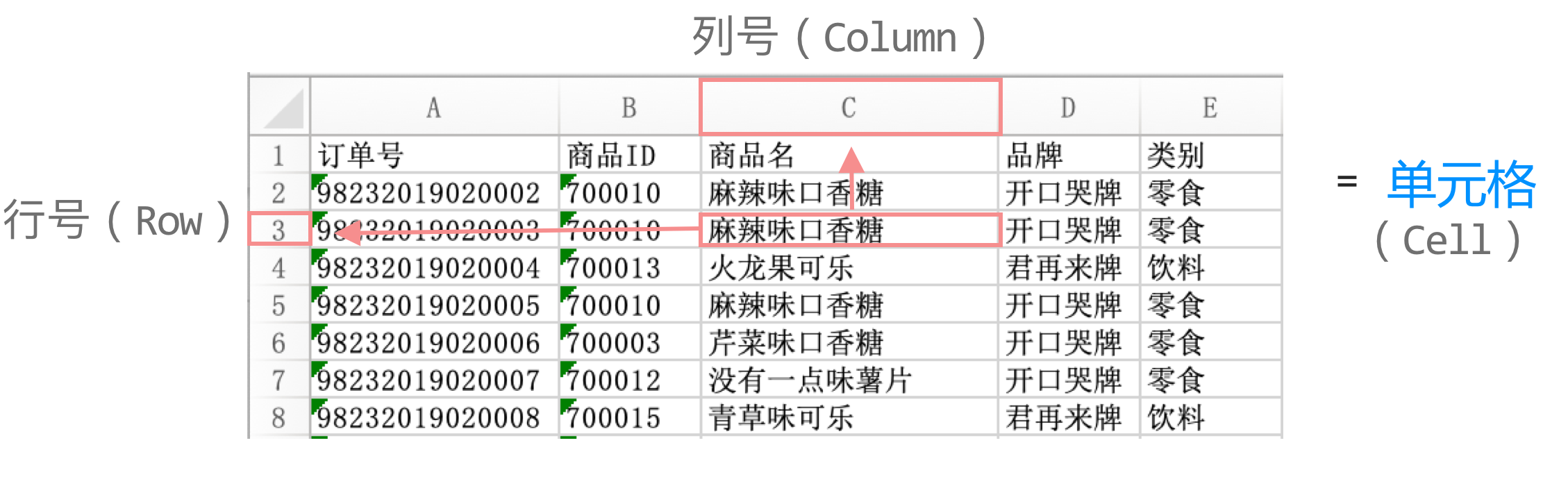
行号默认从数字1开始,并依次递增。
列号默认从字母A开始,依次递增。超过字母Z后,以AA,AB的方式继续计数。

至此,就是Excel表格的基本结构,总结如图所示。
openpyxl 模块
要使用Python对Excel表格进行读取,我们需要安装一个用于读取数据的工具 openpyxl 。openpyxl 是一个用于读、写Excel文件的开源模块。
Excel表格读取
读取工作簿
读取指定路径的工作簿需要使用函数:openpyxl.load_workbook()
openpyxl.load_workbook()函数读取成功后,会返回一个工作簿对象,本例中将这个对象赋值给了变量wb。
# 导入openpyxl模块
import openpyxl
#读取工作目录里名为"2019年1月销售订单.xlsx"的工作簿并赋值给变量wb
wb = openpyxl.load_workbook("2019年1月销售订单.xlsx")
读取指定工作表
如果事先不知道工作簿内有哪些工作表,可以通过访问工作簿的 .sheetnames 属性来获取一个包含所有工作表名称的列表。
具体操作为在变量wb之后添加代码 .sheetnames 。
import openpyxl
wb = openpyxl.load_workbook("2019年1月销售订单.xlsx")
# 使用print输出工作簿中所有的工作表名称
print(wb.sheetnames) # ['销售商品', '销售订单数据']
# 通过工作簿对象wb获取名为“销售商品”的工作表对象,
orderSheet = wb["销售商品"]
读取指定单元格
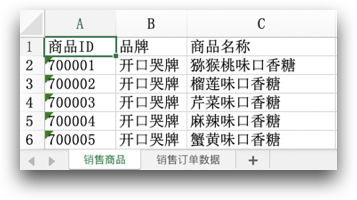
要获取工作表中指定的单元格对象,我们可以通过在中括号 [ ] 内填入列号和行号的方式去获取。
单元格对象除了包含具体的值,还包含相关的函数和属性。
要访问单元格里的值,可以在单元格对象后加一个 .value
import openpyxl
wb = openpyxl.load_workbook("sample.xlsx")
print(wb.sheetnames) # ['sheet1', 'sheet2']
orderSheet = wb["销售商品"]
# 使用print输出 orderSheet 的C5单元格对象
print (orderSheet["C5"]) # < Cell '销售商品'.C5 >
# 使用 orderSheet["C5"].value 输出orderSheet的C5单元格的值
print(orderSheet["C5"].value)
若单元格中包含公式,现有方式读取出的值是公式本身。
若需要读取公式计算后的值,要在读取工作簿的代码部分,传入一个参数: data_only=True ,便可以得出公式计算后的值了。
# 导入openpyxl模块
import openpyxl
# 原打开方式,直接读取公式本身
wb = openpyxl.load_workbook("2019年1月销售订单.xlsx")
orderSheet = wb["销售订单数据"]
# 输出公式本身
print(orderSheet["I3"].value)
# 添加data_only=True打开工作簿,获取公式计算后的值
wb2 = openpyxl.load_workbook("2019年1月销售订单.xlsx", data_only=True)
orderSheet2 = wb2["销售订单数据"]
# 输出公式计算后的值
print(orderSheet2["I3"].value)工作表行数据的遍历

要对整个工作表的每一行数据进行浏览查询,可以使用for循环对工作表对象的行属性(rows)进行遍历。具体代码为 for rowData in orderSheet.rows
这样程序就会以从上到下的顺序,逐个获取到“销售订单数据”工作表内的每一行数据,读取出的每一行数据是由单元格对象组成的元组。
import openpyxl
wb = openpyxl.load_workbook("2019年1月销售订单.xlsx", data_only=True)
orderSheet = wb["销售订单数据"]
# 遍历工作表的所有行数据
for rowData in orderSheet.rows:
# 输出行数据
print(rowData)
# (<Cell '销售订单数据'.A1>, <Cell '销售订单数据'.B1>, <Cell '销售订单数据'.C1>, <Cell '销售订单数据'.D1>, <Cell '销售订单数据'.E1>, <Cell '销售订单数据'.F1>, <Cell '销售订单数据'.G1>, <Cell '销售订单数据'.H1>, <Cell '销售订单数据'.I1>, <Cell '销售订单数据'.J1>)
# 通过索引2获取第3列数据,也就是商品名
productName = rowData[2].value
# 输出商品名
print(productName)列号转数字
使用函数openpyxl.utils.cell.column_index_from_string()来获取工作表列号对应的数字。
遍历行数据时,如果要定位的列数字比较大,比如订单的总价在第 Z 列,列号太大不太容易数的时候就可以使用函数:openpyxl.utils.cell.column_index_from_string(),来获取列号对应的数字.
比如传入参数“I”就会获取到数字9,表示“I”列是第9列。
这个数字减一即可得到对应的索引。因为索引是从0开始的,所以需要减一
import openpyxl
wb = openpyxl.load_workbook("./doc/2019年1月销售订单.xlsx", data_only=True)
orderSheet = wb["销售订单数据"]
for rowData in orderSheet.rows:
productName = rowData[2].value
# print(productName)
priceIndex = openpyxl.utils.cell.column_index_from_string("I") - 1
# print(priceIndex)
price = rowData[priceIndex].value
print(price)
# 总价
# 5
# 20
# 40
# ...Excel表格写入
创建工作簿
使用openpyxl.Workbook()函数即可创建一个新工作簿。
创建成功后,新创建的工作簿对象会被返回。为了方便之后对这个工作簿进行操作,将这个对象赋值给一个变量newWb。
可以访问sheetnames字段来获取工作簿内所有的工作表名称,使用openpyxl.Workbook()创建的工作簿里面,都有一张默认的工作表,名称为Sheet。
import openpyxl
# 创建一个新工作簿并赋值给变量newWb
newWb = openpyxl.Workbook()
# 输出新工作簿内所有的工作表名称
print(newWb.sheetnames) # ['Sheet']
修改工作表名称
先通过变量newWb使用中括号 + 工作表名称获取这个工作表对象,然后把这个对象赋值给变量aSheet。
通过对工作表对象的 .title属性进行赋值,即可修改工作表的名称。
import openpyxl
newWb = openpyxl.Workbook()
# 将名为Sheet的默认工作表赋值给aSheet变量
aSheet = newWb["Sheet"]
# 将aSheet工作表名称修改为“A平台”
aSheet.title = "A平台"
创建工作表
通过工作簿对象使用create_sheet()函数可以创建一个名称为Sheet的工作表。
若名为Sheet工作表已经存在,则会在Sheet后依次添加数字,比如Sheet1,Sheet2。
在创建时如需要指定工作表名称,可以将需要指定的工作表名称作为参数传入create_sheet()函数。
import openpyxl
newWb = openpyxl.Workbook()
# 不指定名称创建工作表
newWb.create_sheet()
# 指定创建的新工作表名称为"陌上花"
newWb.create_sheet("陌上花")
# 输出所有的工作表名称以检查是否创建成功
print(newWb.sheetnames) # ['Sheet', 'Sheet1', '陌上花']新创建的工作表对象会在函数调用后返回,在这里也可以直接分别赋值给变量bSheet和cSheet,方便之后操作使用
# 创建 B平台 的工作表并赋值给变量bSheet
bSheet = newWb.create_sheet("B平台")
# 创建 C平台 的工作表并赋值给变量cSheet
cSheet = newWb.create_sheet("C平台")Excel设置单元格的值
每一个工作表都有一个表头,分别是“商品名”、“月份”和“销售额”。
本质上,每一个表头也就是一个一个单元格组成的。要修改每个工作表的表头,就需要用到“设置单元格的值”这个知识点。

可以通过“工作表对象["列号行号"].value”这种方式来获取指定的单元格的值。
而直接把要设置的值赋值给.value属性,就可以设置或修改这个单元格的值了。
# 设置aSheet里A1单元格的值为“编号”
aSheet["A1"].value = "编号"
aSheet["B1"].value = "月份"
aSheet["C1"].value = "销售额"
# 输出A1单元格的值以检查是否设置成功
print(aSheet["A1"].value)
可以使用for循环对工作簿对象内的worksheets属性进行遍历,以达到逐个访问所有工作表并设置表头的目的
# 使用for循环遍历工作簿对象的worksheets属性
for sheet in newWb.worksheets:
# 给每一个工作表设置表头
sheet["A1"].value = "商品名"
sheet["B1"].value = "月份"
sheet["C1"].value = "销售额"
保存工作簿文件
通过工作簿对象使用save() 函数,将文件保存路径作为参数,即可将工作簿保存到指定的文件路径。 一般将工作簿存储成后缀名为.xlsx的文件。
如果指定路径的文件已经存在,使用save()函数会覆盖原有文件。
# 将工作簿保存到指定路径
newWb.save("/Users/chixm/data/汇总.xlsx")Excel添加行数据
想要添加一整行数据可以通过工作表对象使用append()函数。
append()函数会在现有工作表内数据的最后一行之后再添加一行数据。
append()函数只有一个参数,该参数是一个列表或者元组。
使用函数后,列表或元组内的数据会按照顺序逐个添加到目标行中。
import openpyxl
# 读取工作簿和工作表
wb = openpyxl.load_workbook("怪物数值.xlsx")
sheet = wb["东胜神州"]
# 通过append()函数传入一个元组添加一行数据
sheet.append(("D10002", "白鼠", 600))
# 保存工作簿到原路径
wb.save("怪物数值.xlsx")