Python基础 – for循环
for循环的基础操作
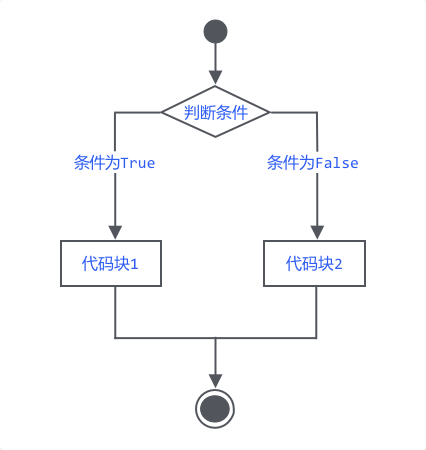
循环是计算机程序的三大语句结构之一。
它是在满足条件的情况下,反复执行某一段代码的计算过程。
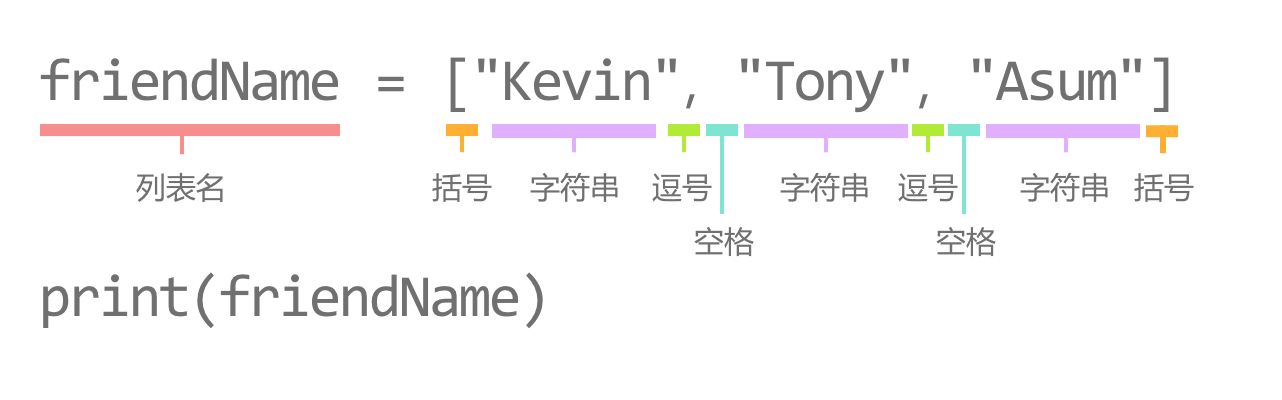
假设,现在我们需要输出以下列表中的每个元素,你会怎么做呢?
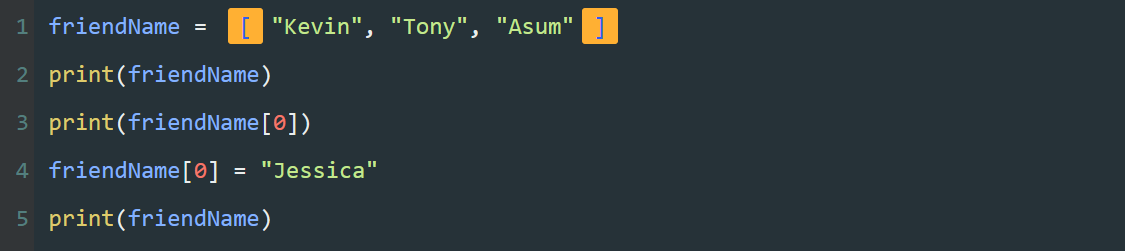
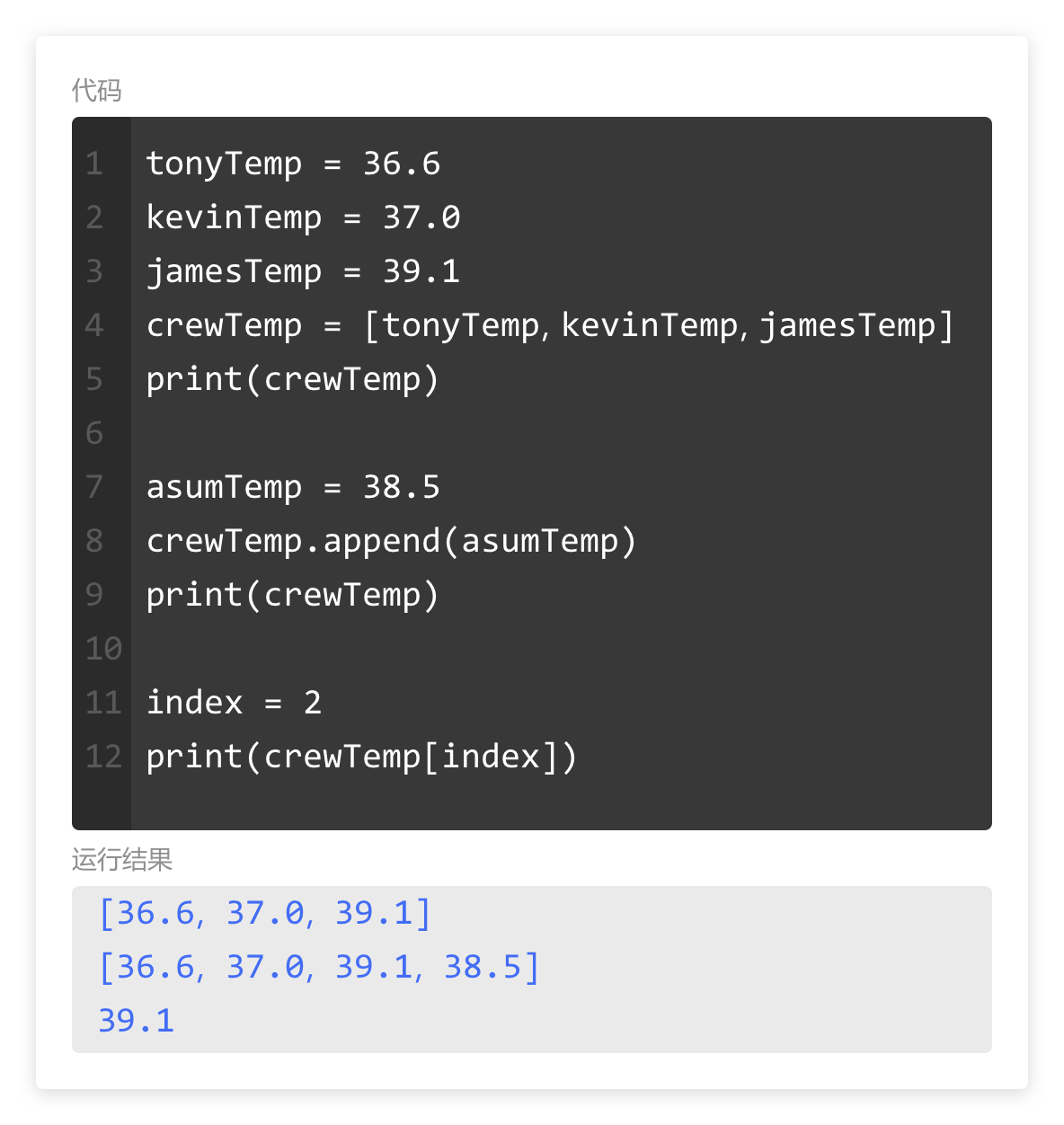
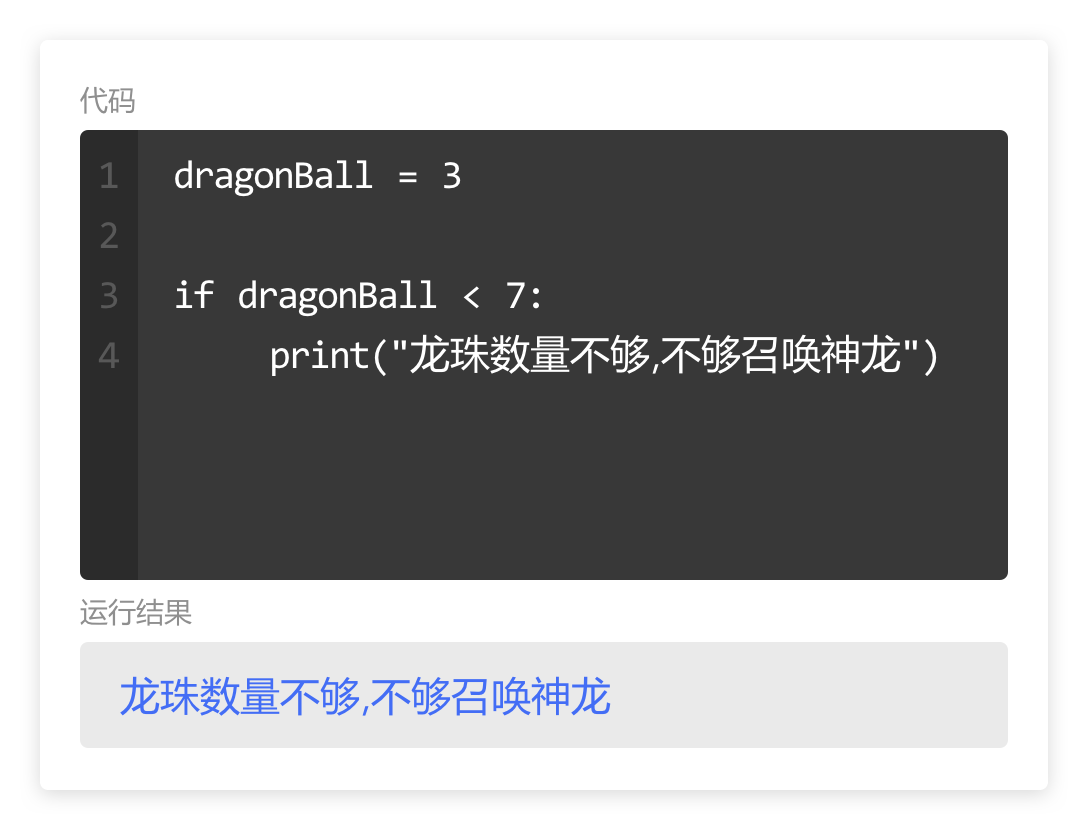
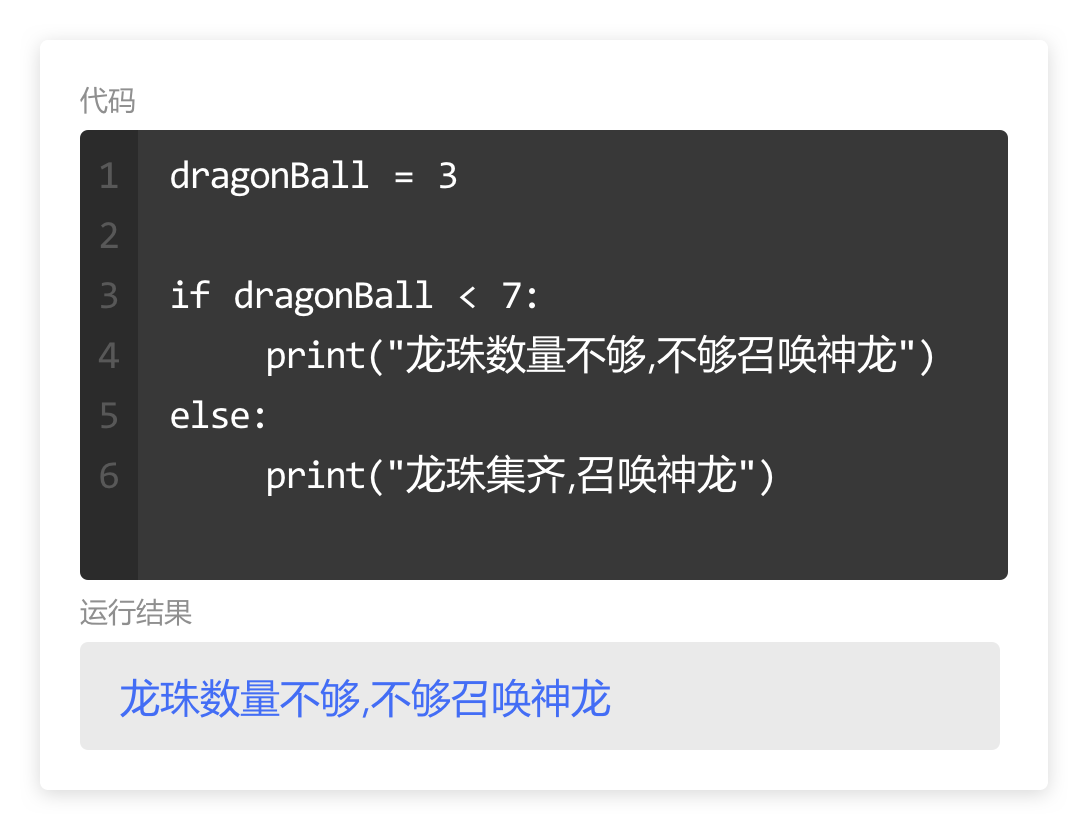
numberList = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
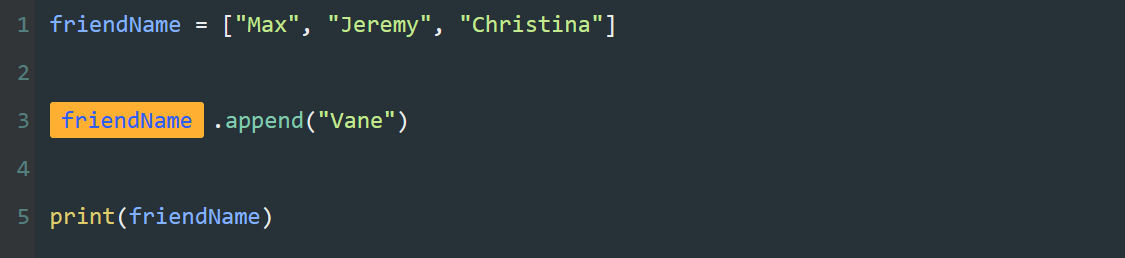
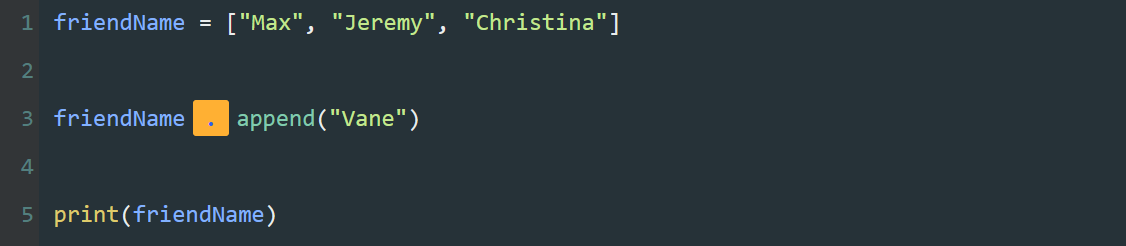
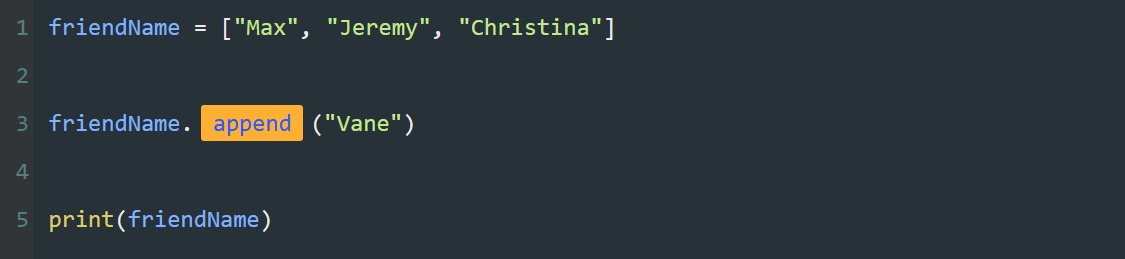
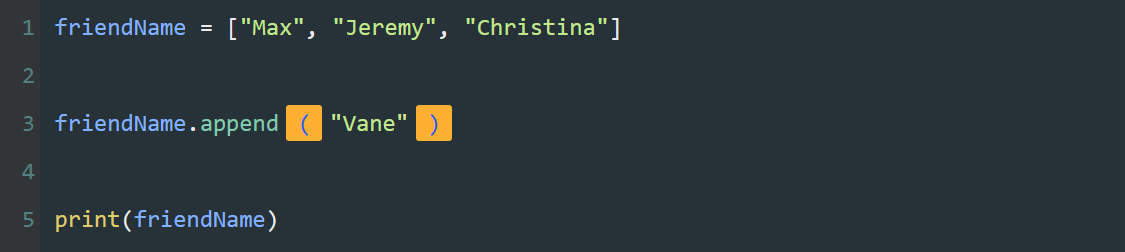
可以通过索引,将列表中的元素一个一个的输出。
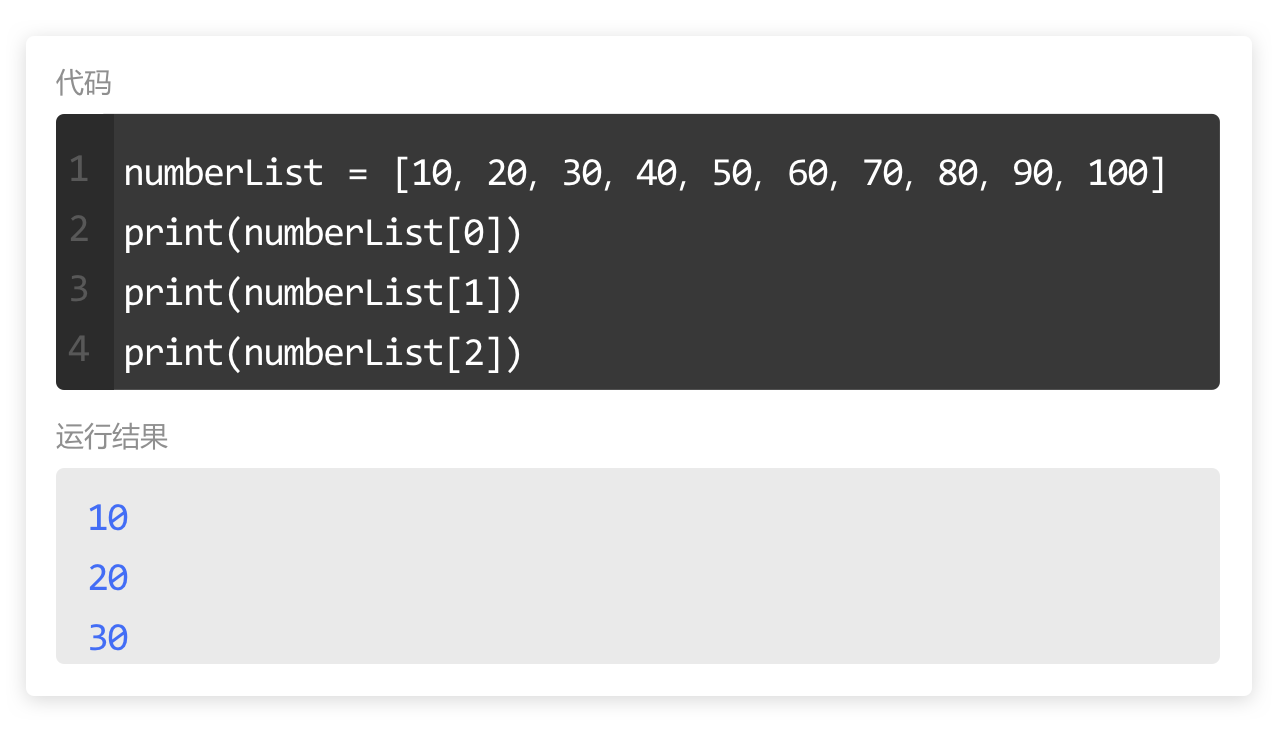
如果列表中的元素不止五项,而是几十项,甚至是几百项,我们还要大量重复编写print() 和列表索引么?这可太麻烦了。
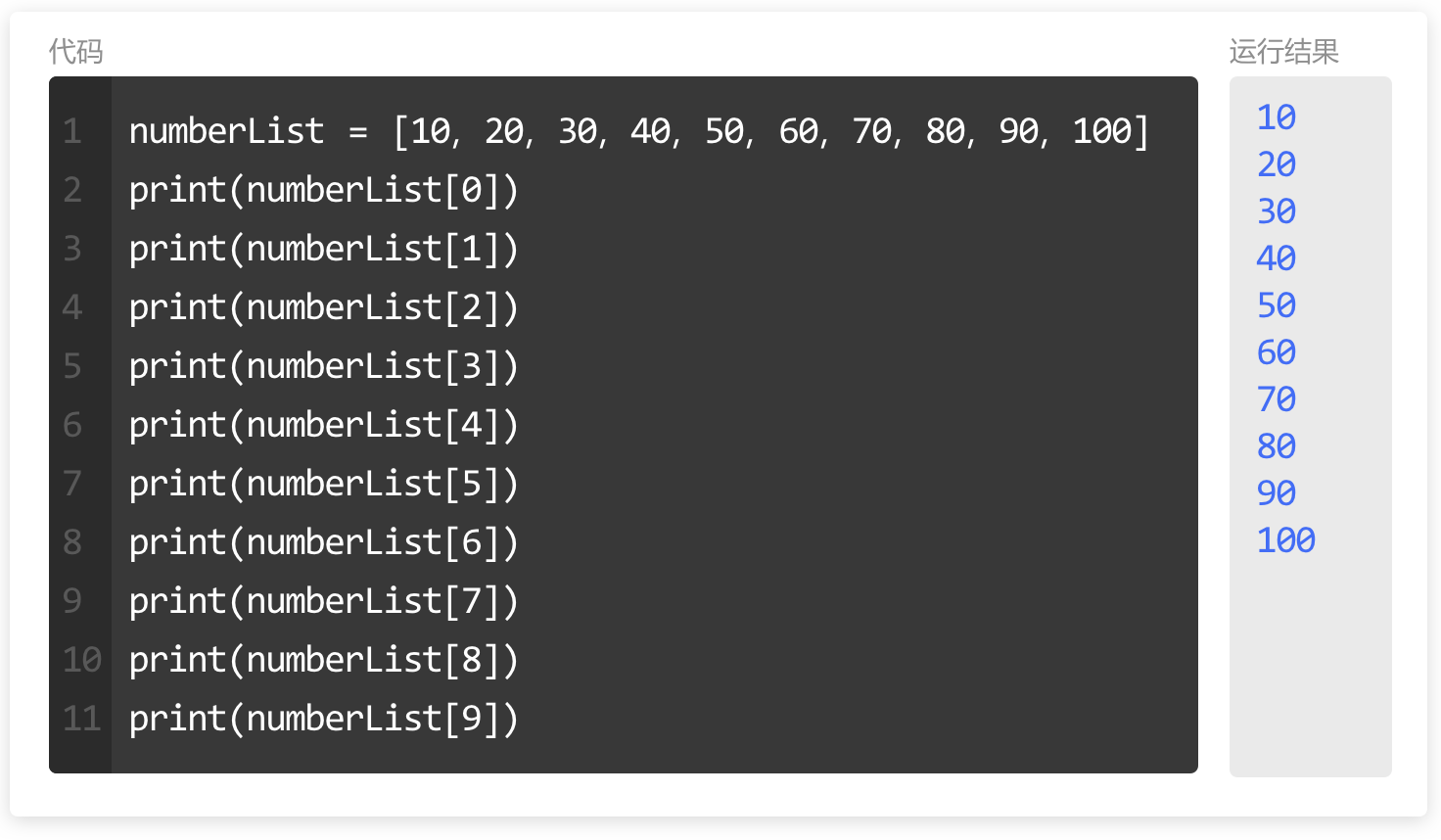
接下来,我们试着用【循环】简化这段代码。
numberList = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
for number in numberList:
print(number)原本需要编写 10 行的代码,现在使用【循环】后,编写方便了很多。
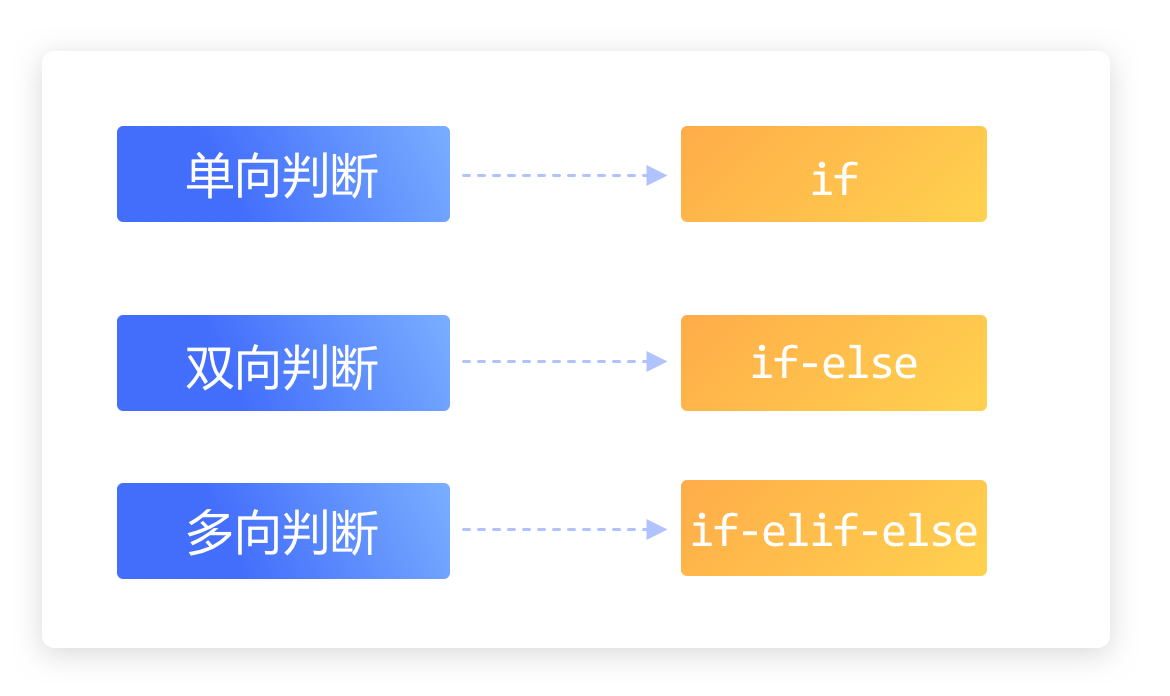
在 Python 中,循环语句有两类:
for 循环和 while 循环
for 循环的结构
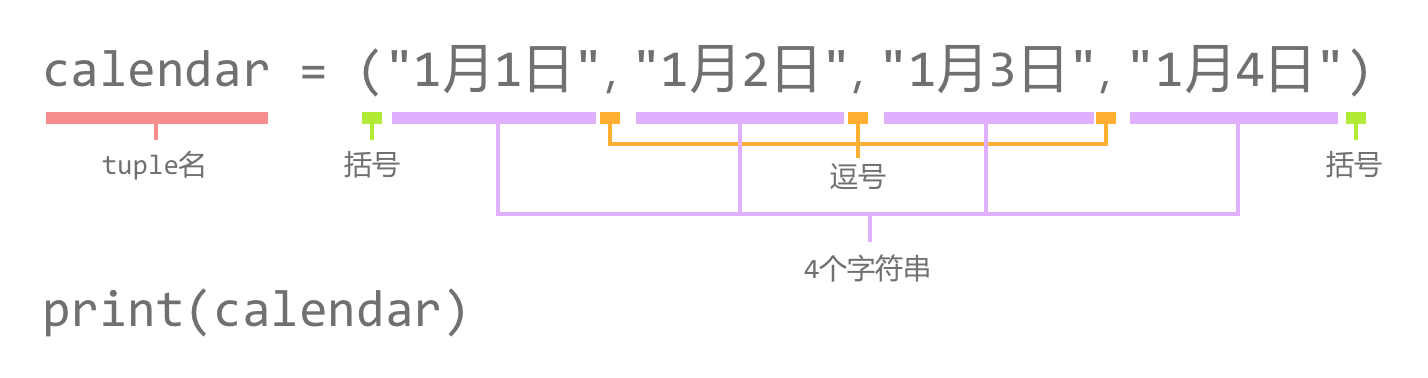
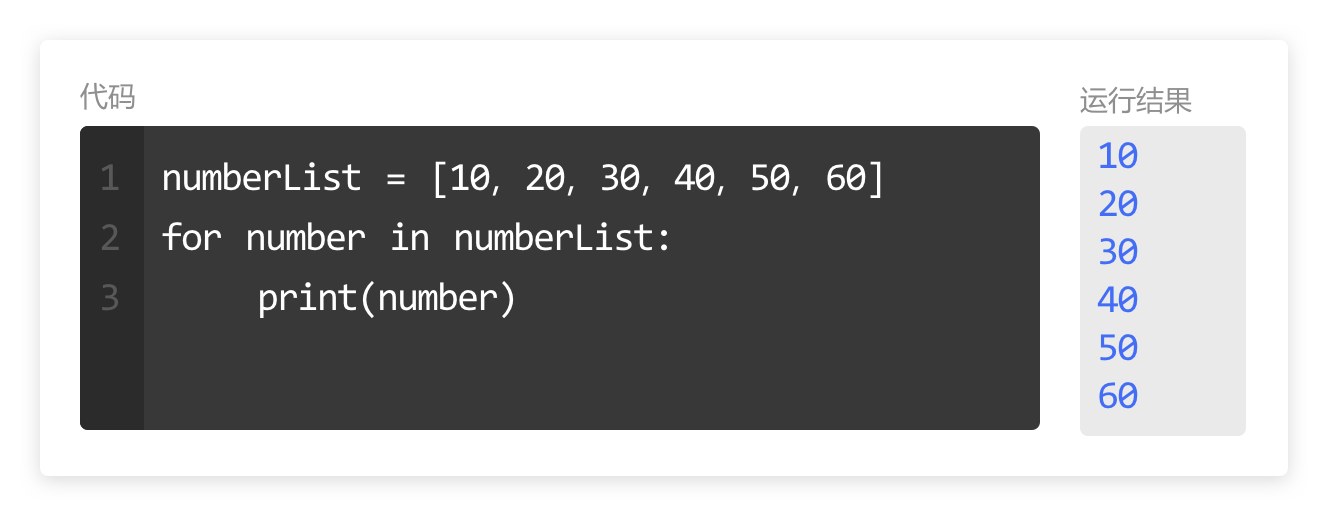
numberList = [10, 20, 30, 40, 50, 60]
for number in numberList:
print(number)代码的作用
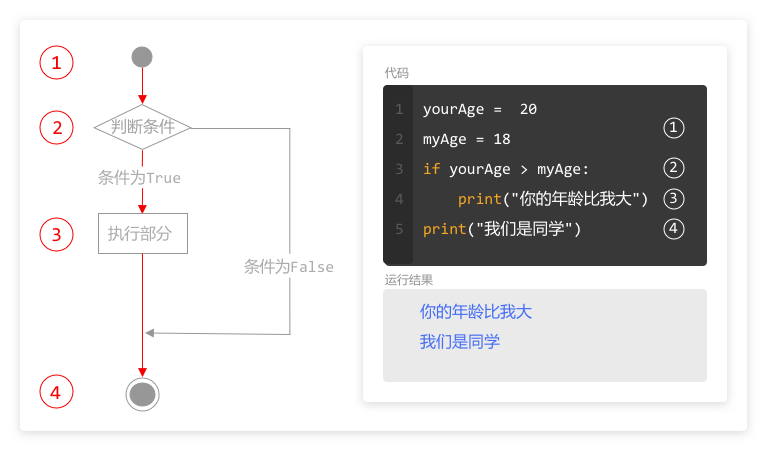
这三行代码使用了 for 循环将列表 numberList 里面的所有元素全部输出出来。
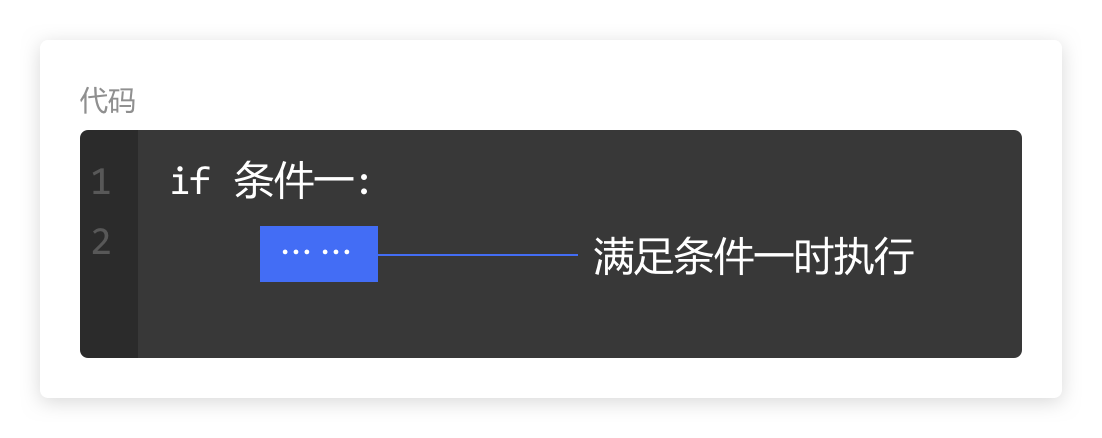
for
使用关键字 for,表明要在这里开始执行“for循环”的代码结构。

in
使用关键词 in,和 for 搭配,表明我们要把 in 后面的列表里面的数据元素赋值给前面的变量。

变量
表示一个变量,在 for 循环里面用来存储列表中的元素。
在本例代码中,列表 numberList 中有 6 个元素,变量 number 会被赋值 6 次。

列表
列表中里面的元素会被分别赋值给变量,直到最后一个元素完成赋值,循环才结束。

冒号
循环语句的固定格式,表明接下来缩进的代码是每次循环都要执行的。

缩进
同样缩进的代码就是一个代码块,在每次循环中都要执行。
在这里,建议缩进四个空格,和 if 语句类型的缩进一样,保持同一种代码风格。
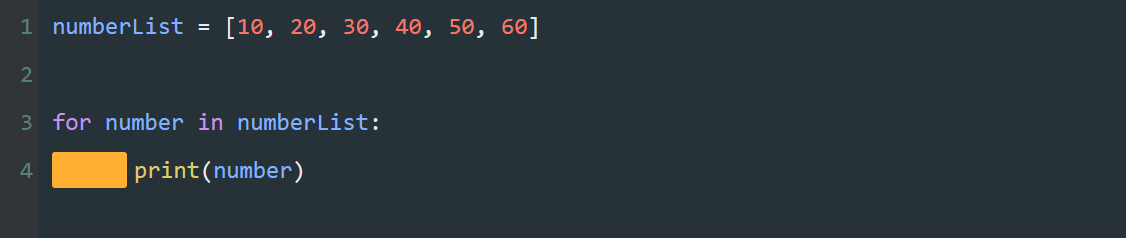
循环内
循环内的代码块,直到列表 numberList 中的元素被全部赋值完,循环才结束。
在本例中,由于列表 numberList 中的元素有 6 个,print()就要执行 6 次。

代码小结
通过如下格式在代码中使用for循环

# TODO 定义列表fruitList
fruitList = ["apple", "grape","cherry"]
# TODO for循环列表fruitList,将元素赋值给变量fruit
for fruit in fruitList :
# TODO 输出变量fruit
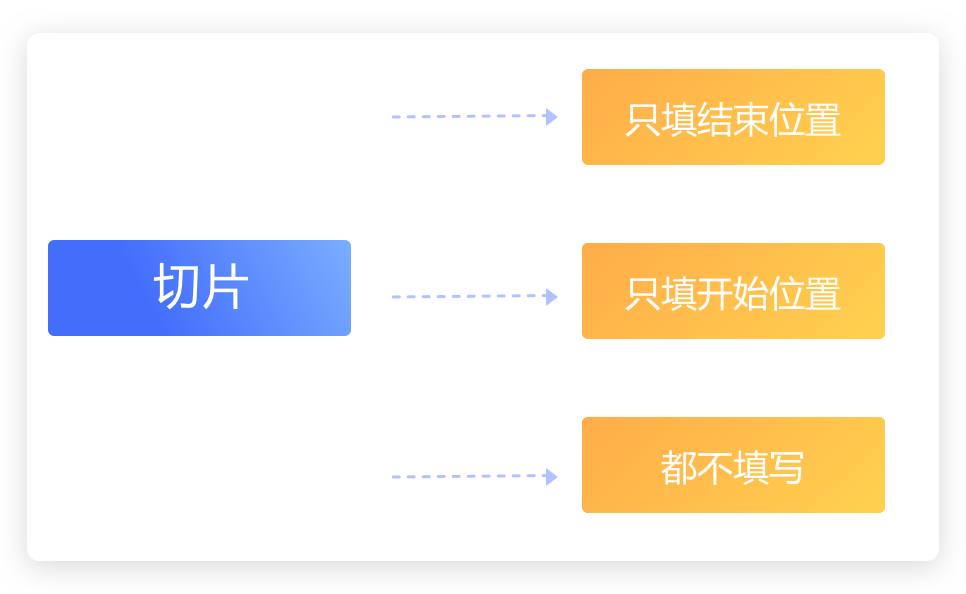
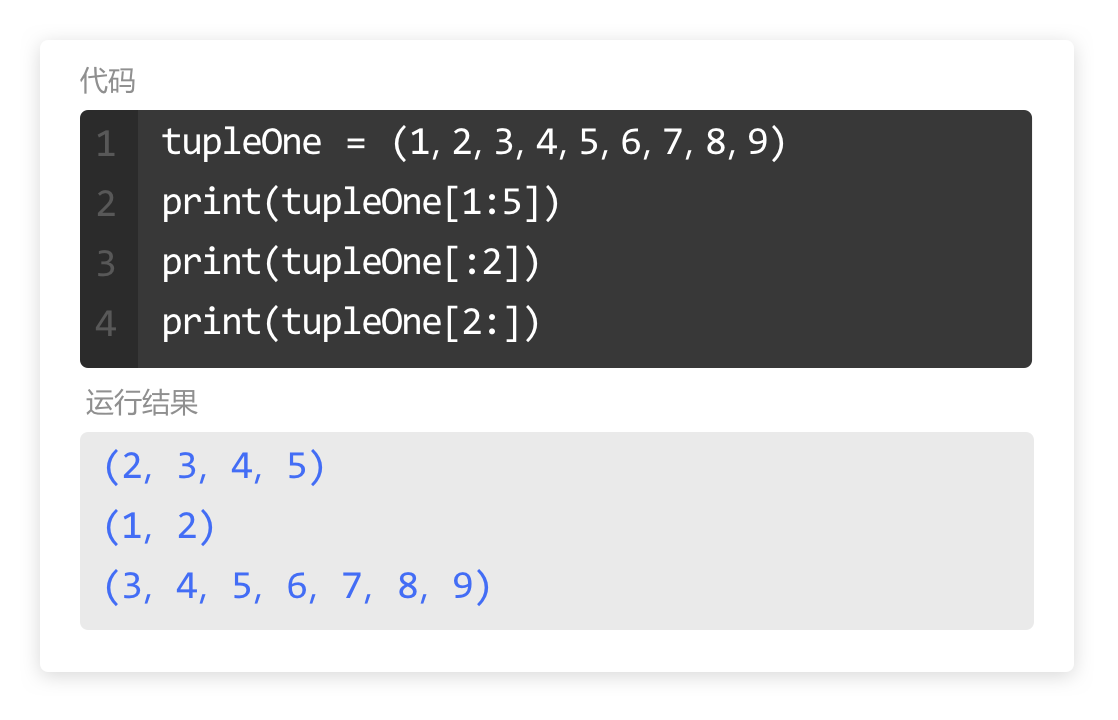
print(fruit)# 使用 for 循环,利用切片获取列表中的第二项到第六项元素,分别赋值给一个变量 number,然后使用 print() 输出这个变量。
# 定义列表numberList
numberList = [10, 20, 30, 40, 50, 60]
# TODO for循环列表中的第二项到第六项元素
for number in numberList[1:] :
# TODO 输出列表的元素
print(number)for 循环的运行流程
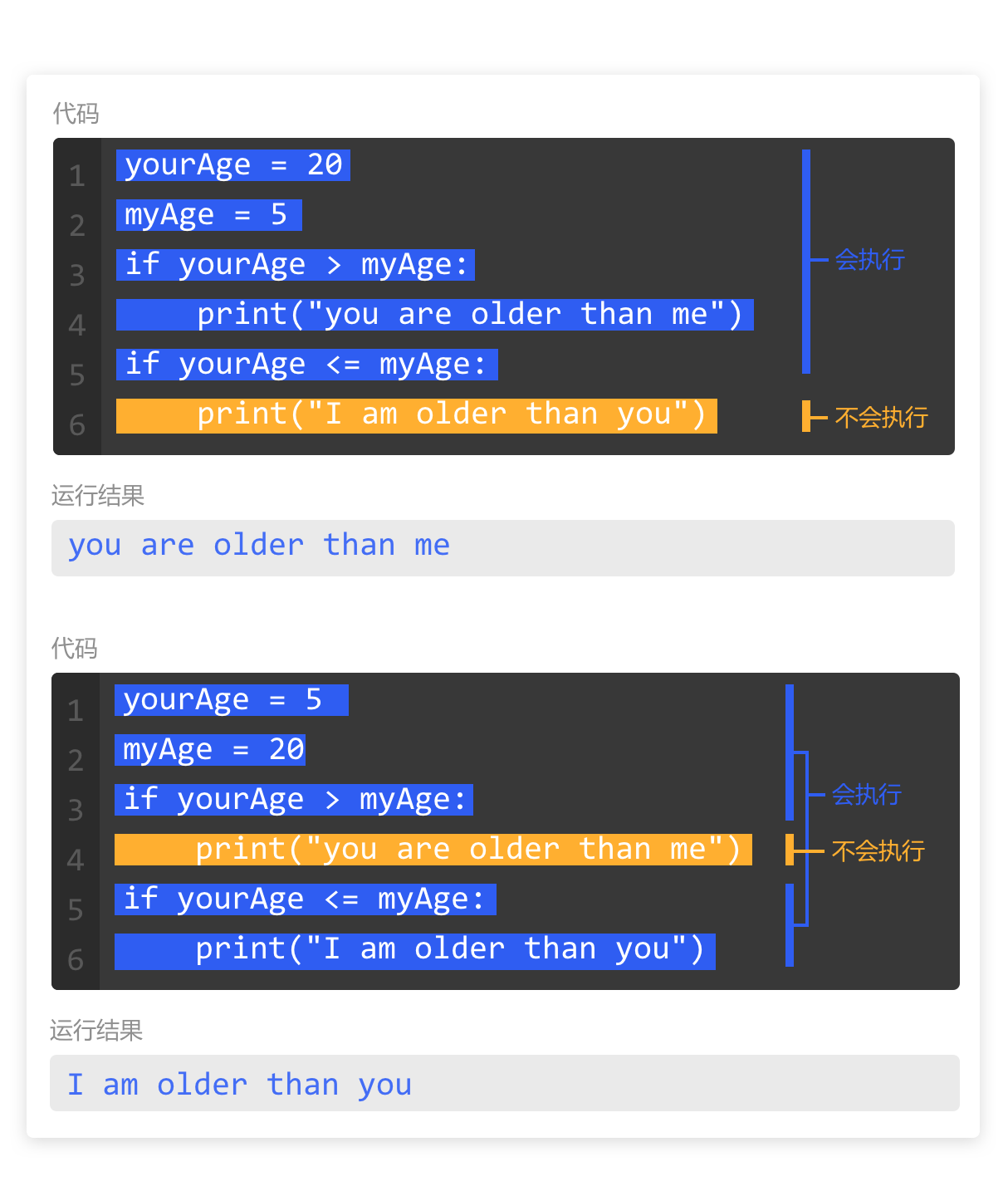
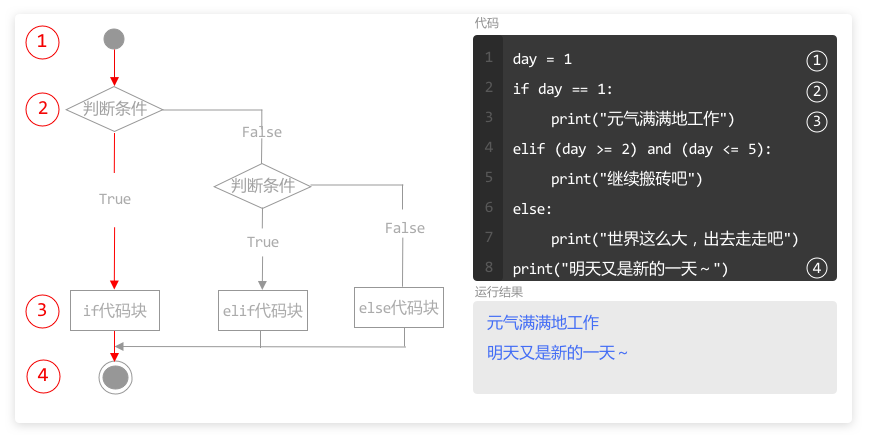
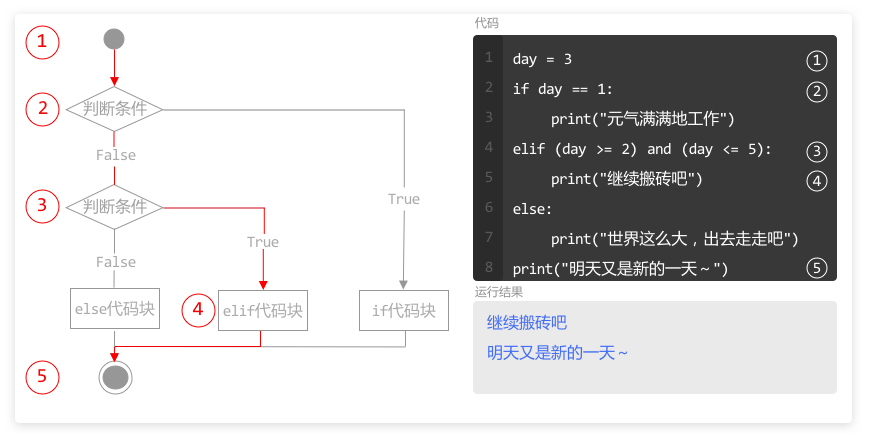
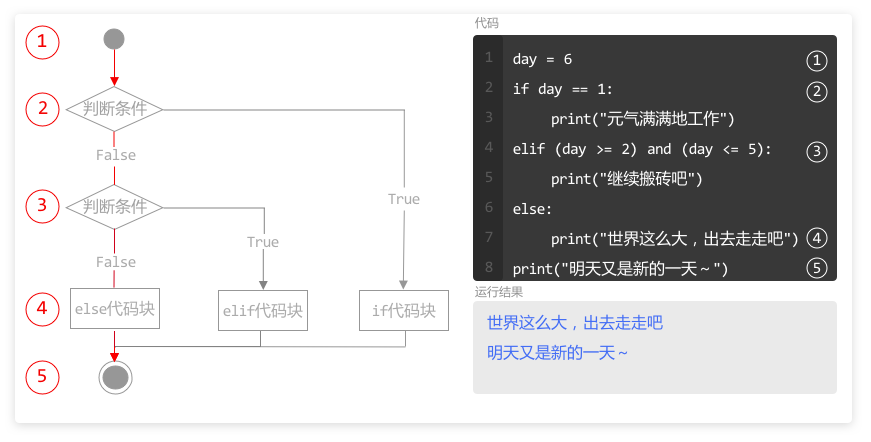
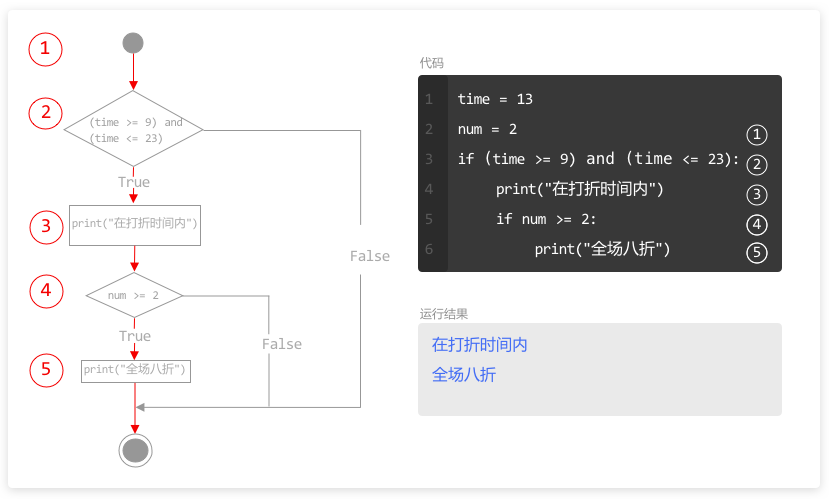
当程序执行完 for 循环后,如果同一层级(缩进一致)还有代码未执行,则按照顺序,继续自上而下执行。

本例中,第2行和第3行的循环,执行 6 次以后,列表 numberList 中所有元素都被访问完了,for 循环结束。
变量 number 被赋值 6 次,循环结束后,变量 number 的值为 60。
程序继续执行下面和 for 循环处于同一层级代码,输出变量 number,在运行结果中就输出了 60。

for 循环的灵活之处在于,它会根据列表中的元素个数,自动调节循环的次数。
也就是说,for 循环能自动遍历一个列表里面的所有元素。
遍历
遍历是指通过某种顺序对一个数据结构中的所有元素进行访问。
for循环不仅可以遍历列,还可以遍历字典、元组、甚至字符串等数据结构。
遍历元组和字符串与遍历列表的代码几乎一样,也是逐个获取元组或字符串的每个字符。

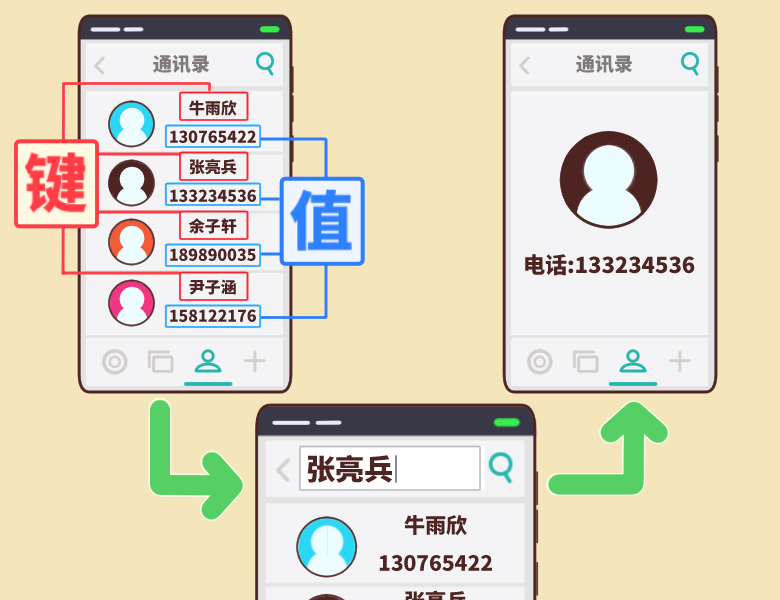
for 循环遍历字典稍微有一些区别。
字典是键值对的组合,那么对字典的遍历就包含【键,值,键和值】三种情况。
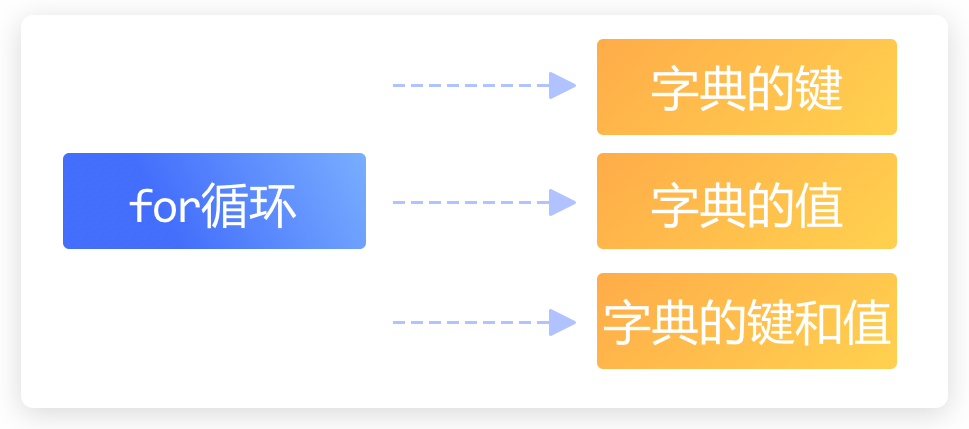
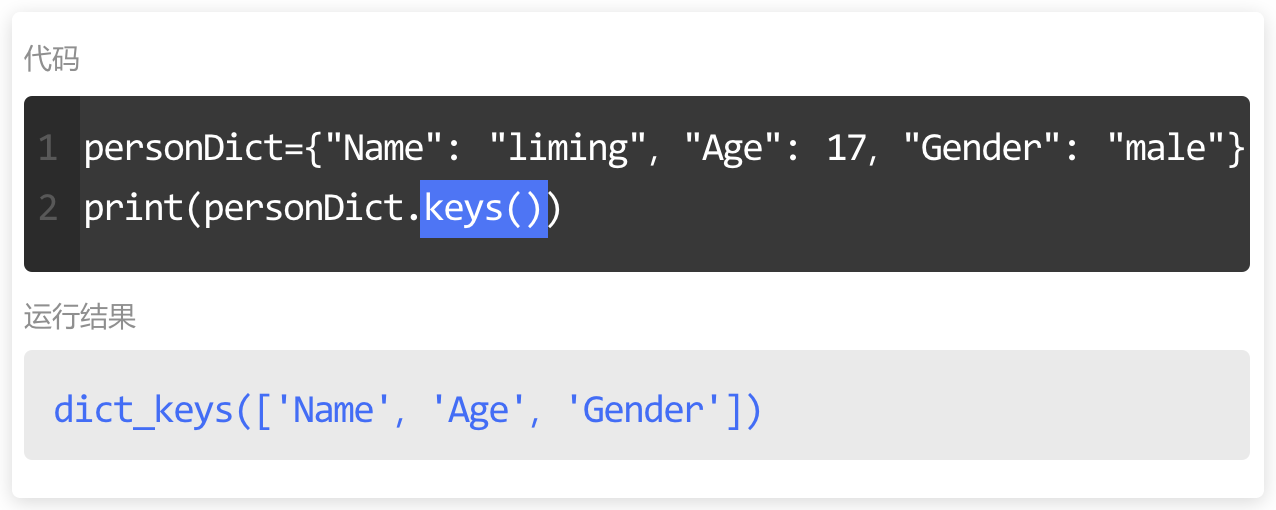
遍历字典的键
for 循环遍历字典的键,有两种方法可以使用:
for 循环遍历字典;
这个方法和 for 循环遍历列表的格式类似。for循环遍历字典中的所有键;
使用 for 循环遍历 dict.keys(),将字典中的键赋值给变量,再通过 print() 输出变量。

遍历字典的值
遍历字典的值,可以通过查字典的方式,也就是通过字典的键找到对应指定的值。
首先使用 for 循环遍历字典,将键赋值给变量,通过dict[键]的方式找到对应的值,并赋值给新的变量。
接着使用 print()输出这个变量,即可遍历字典的值。

遍历字典的键和值
上面演示的是使用 for 循环遍历字典的键和字典的值,如果想要同时输出字典的键和值,该怎么办呢?
这时,可以在循环内部分别输出字典的键和对应的值。
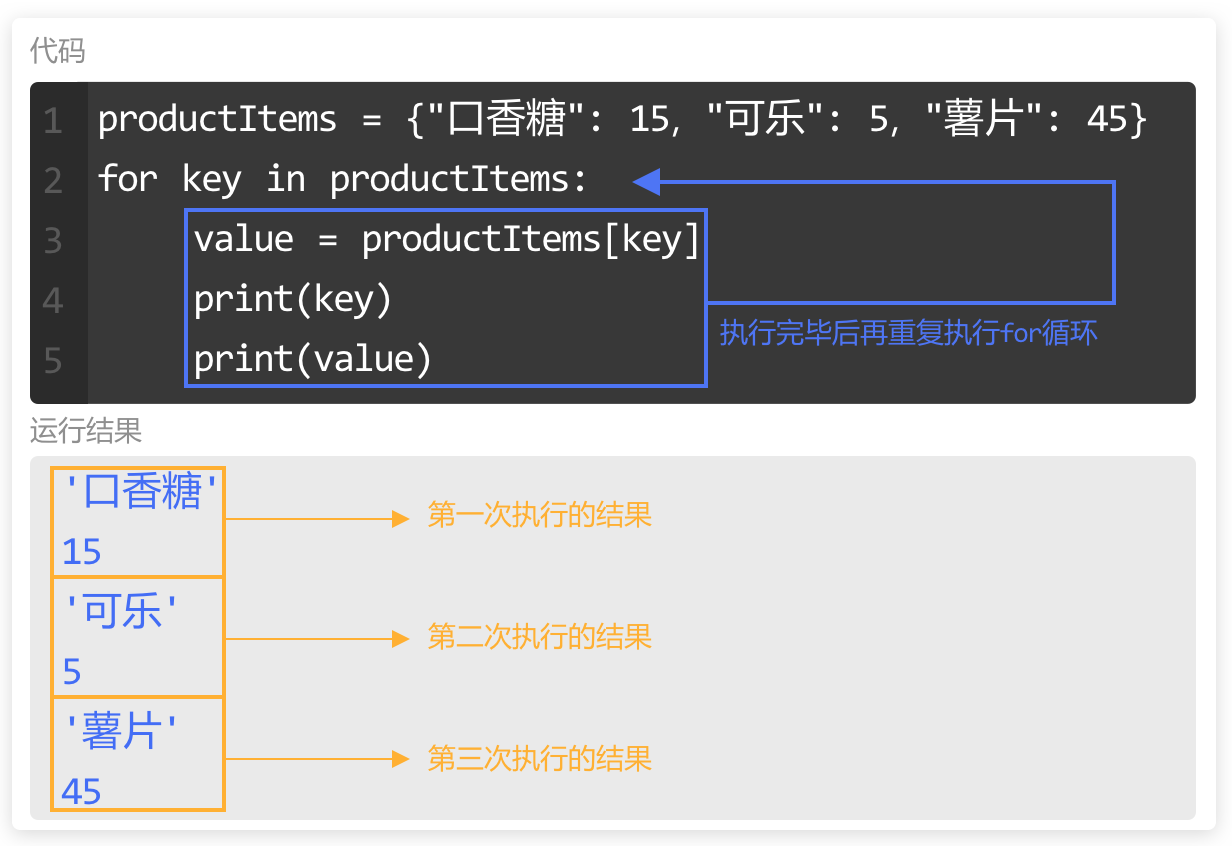
注意,在 for 循环中,一次循环会把循环内的代码全部执行完后,再开始下一次循环。

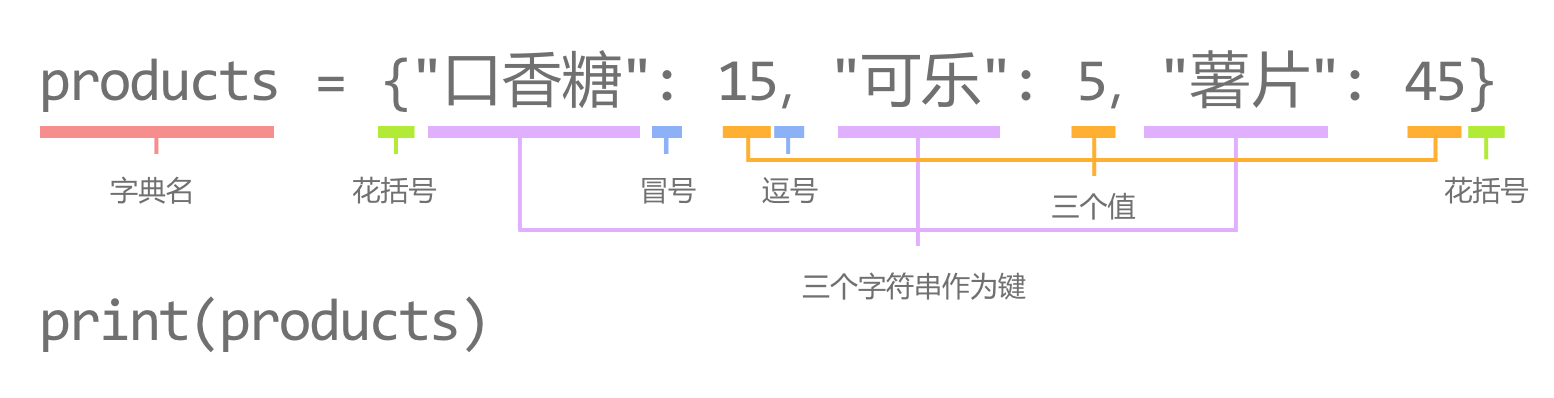
在本例中,for 循环遍历字典productItems,在第一次循环中,变量 key 被赋值为"口香糖"。
进入循环中,第3行代码获取到"口香糖"对应的值 15,并赋值给变量 value,在第4行和第5行分别输出"口香糖"和15。
接着进入第二次循环,变量 key 被赋值为"可乐",就这样执行完循环内的代码,再开始下一次循环,直到循环结束。
# 修改年龄
# 刘老师在录入学生年龄时,不小心输入错了学生年龄,现在她想要把学生的年龄批量修改,这该如何操作呢?
# 1. 首先定义一个叫作 studentAge 的字典,{"Gary": 14, "Adam": 13, "Jack": 15, "Max":13, "Tim":14}。
# 2. for 循环遍历字典 studentAge,将字典的键赋值给变量key;
# 2.1 利用字典键查找值的方法,将字典中全部的值修改为 16。
# 3. for 循环结束后,输出字典studentAge。
# TODO 定义字典studentAge
studentAge = {"Gary": 14, "Adam": 13, "Jack": 15, "Max":13, "Tim":14}
# TODO for循环字典studentAge
for key in studentAge :
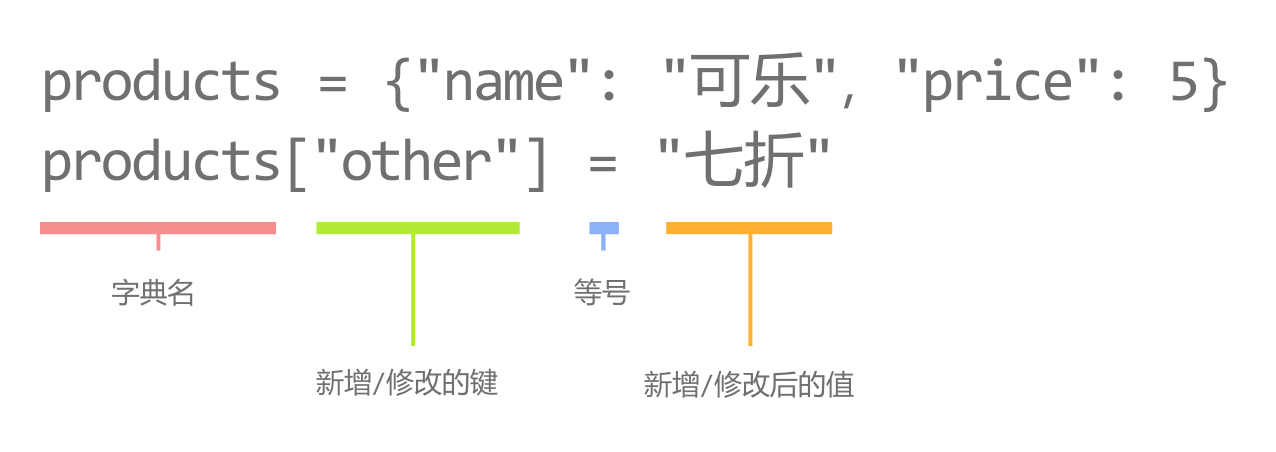
# TODO 修改字典的值为16
studentAge[key] = 16
# TODO 输出字典studentAge
print(studentAge)studentAge = {"Gary": 14, "Adam": 13, "Jack": 15, "Max":13, "Tim":14}
for key in studentAge :
print(key)
print(studentAge[key])for循环的复杂应用
学习了 for 循环遍历列表、字典等数据的方式。
了解学习下for 循环与“累加” 、if 判断和“计数器”的结合运用。
学过运用四则运算,计算 a 和 b 的和。
如果,要计算列表 jdList 中所有元素的和,该怎么操作呢?
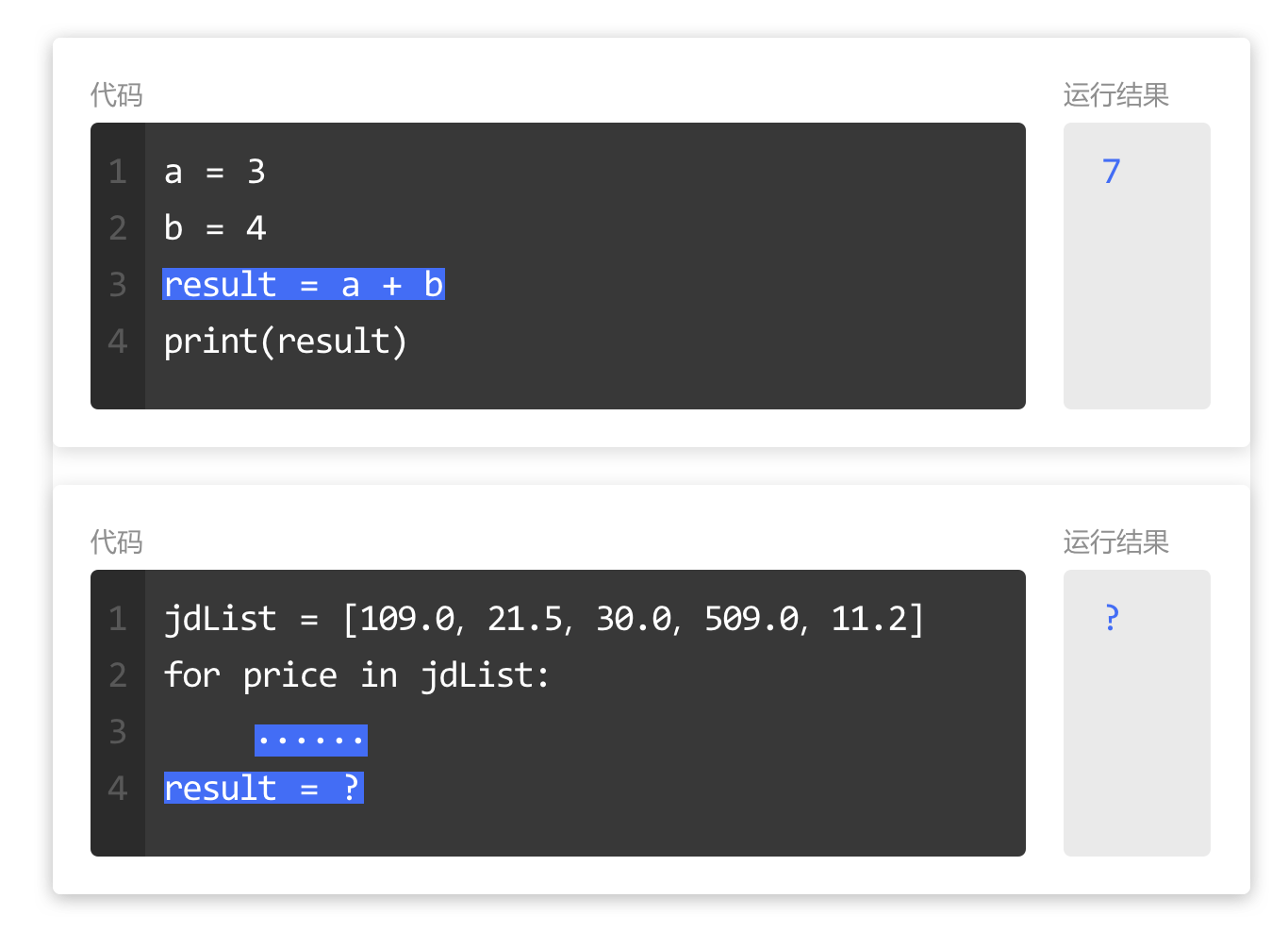
这种情况下,了解下"累加"的概念。
什么是“累加”呢?
例如,往瓶子里不断地放硬币的过程,就是“累加”。

for 循环与“累加”
jdList = [3, 1.5, 4, 2]
total = 0
for price in jdList:
total = total + price
print(total)代码的作用
这5行代码的功能就是,计算列表中的所有元素的总和并输出。
定义列表
第1行定义了列表 jdList ,列表中的四个元素都是可计算的数值(整型或浮点型)。

初始值
我们需要用一个变量来存储总和,第2行定义变量 total ,将0赋值给变量,这个过程就是设置初始值。
注意:这里的初始值需要定义在 for 循环的外侧,若定义在 for 循环中,每次循环变量都会重新赋值。

遍历列表
第3行使用for...in... 结构遍历列表 jdList ,依次取出每个元素。
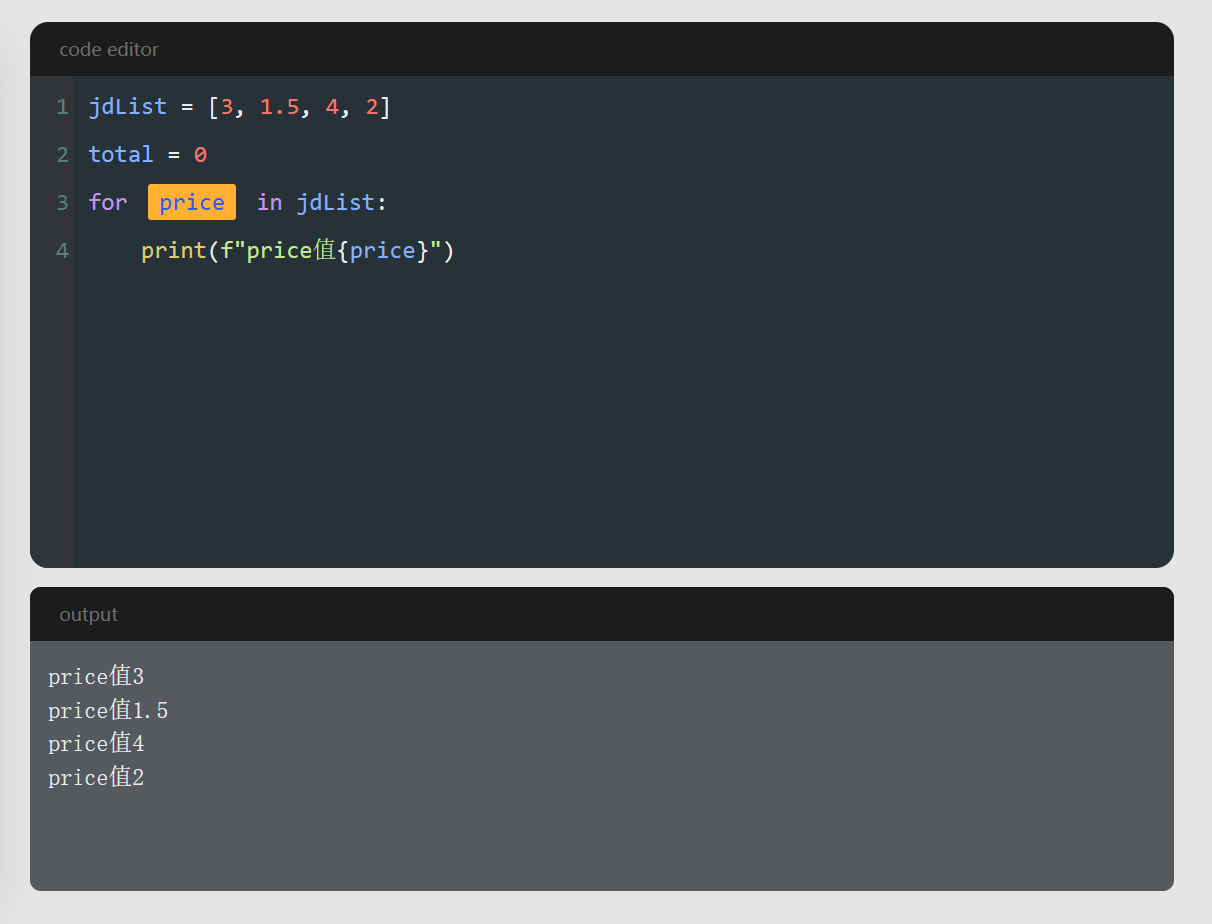
累加
第4行使用加法,计算 total 和 price 的和,再赋值给 total。
注意:根据四则运算规则,先计算等号("=")右边内容,再将计算结果赋值给左边变量。

(累加计算过程)
for循环第一次取出的元素price的值为3
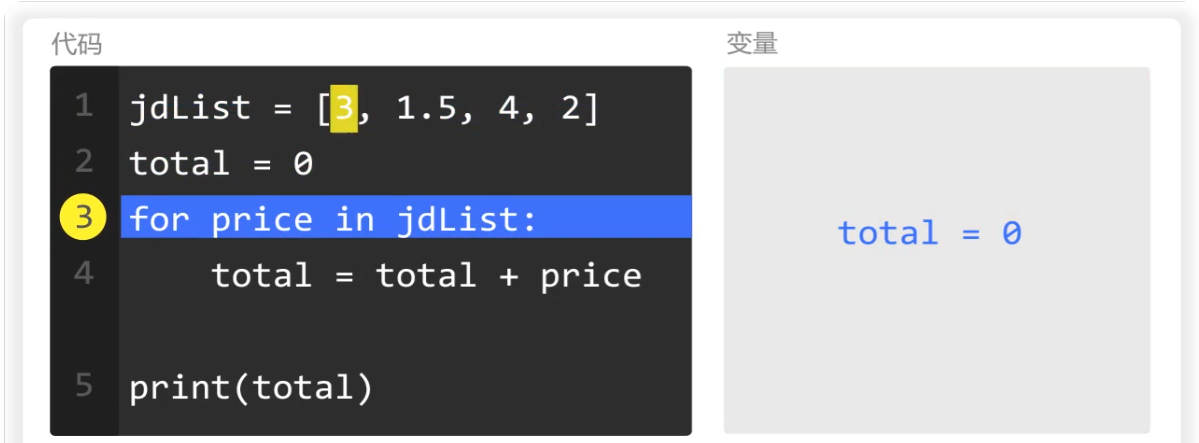
然后第一次对列表中的元素进行累加,total的初始值为0,price的值为3,两者相加和为3,赋值给total

第二次循环时,price的值为1.5
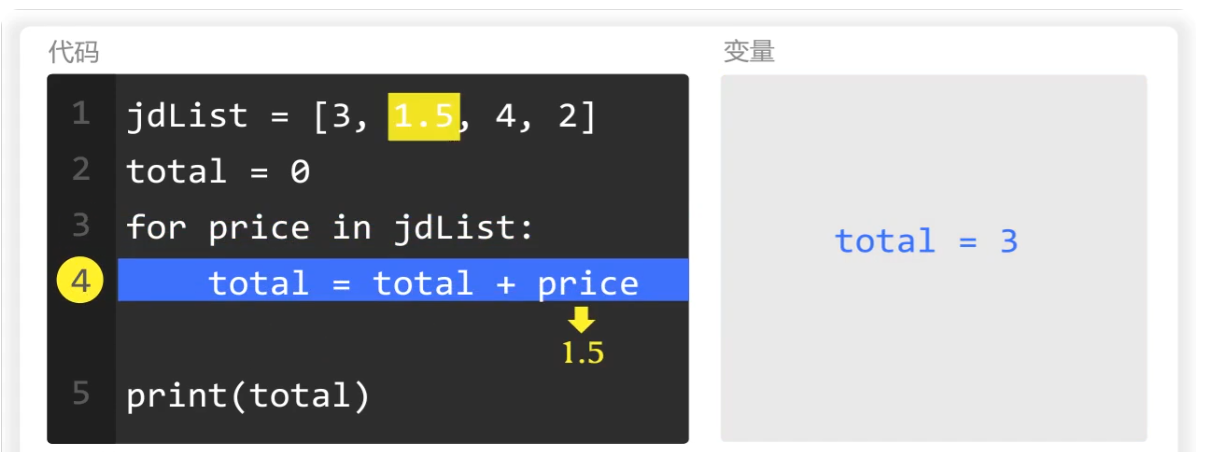
total的值为3,两者相加和为4.5,再赋值给total

第三次循环时,price的值为4
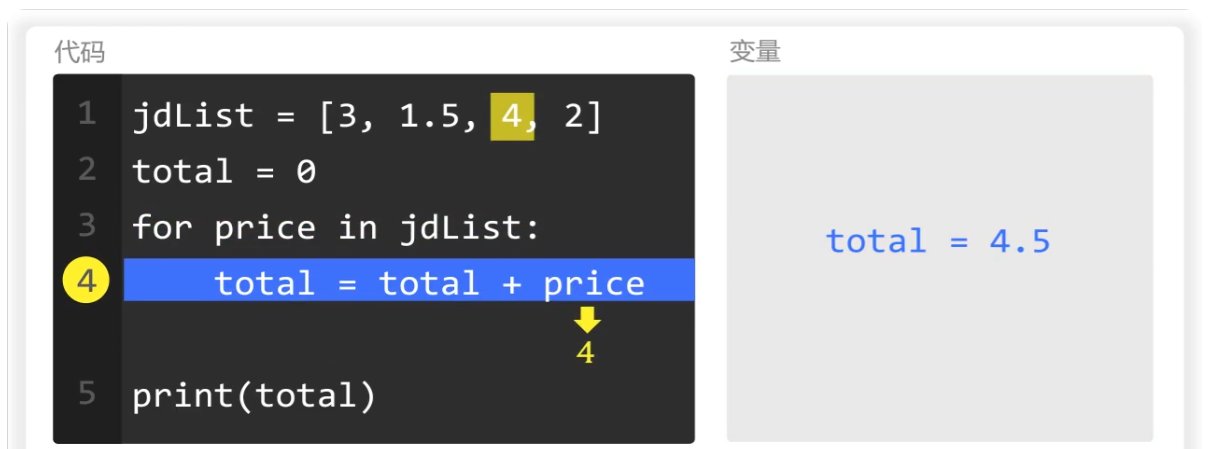
total的值为4.5,两者相加为8.5
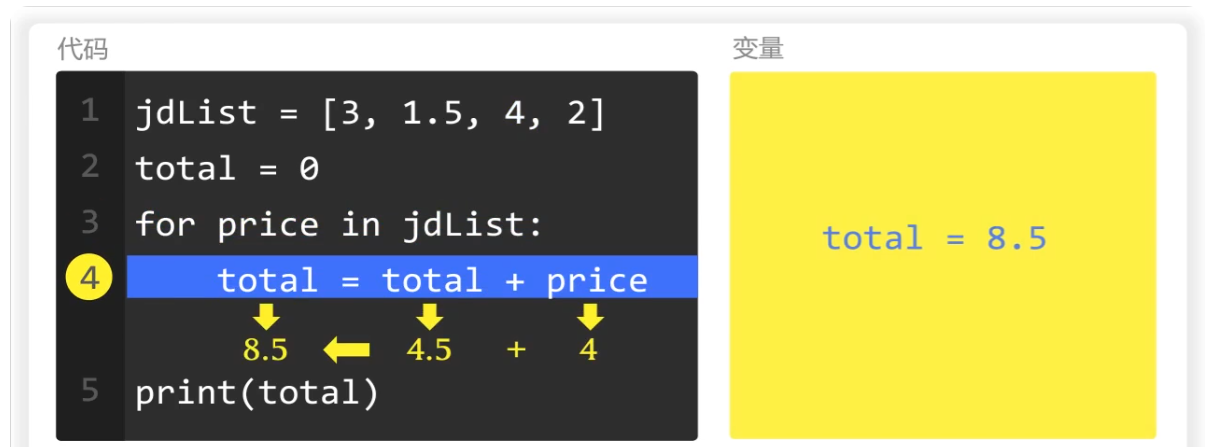
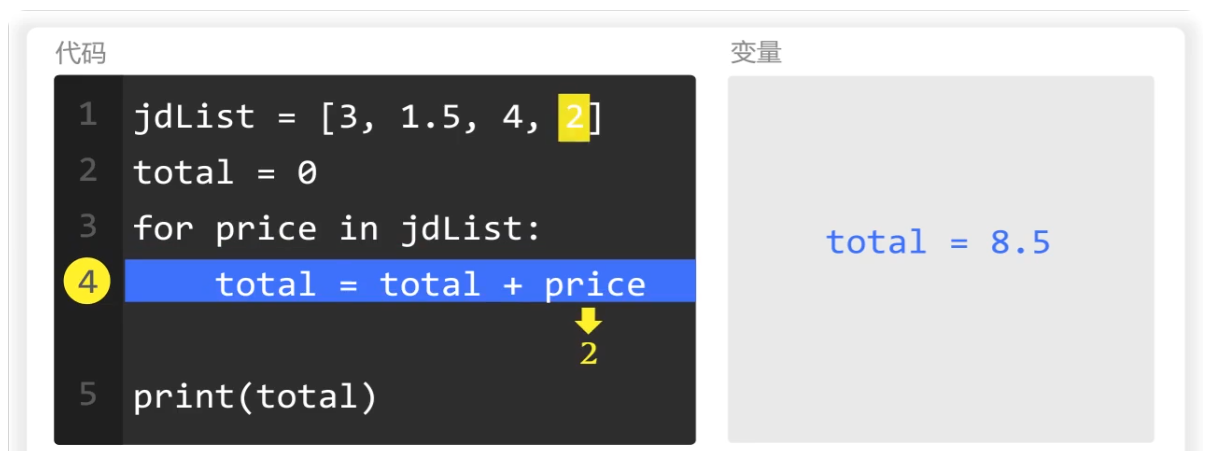
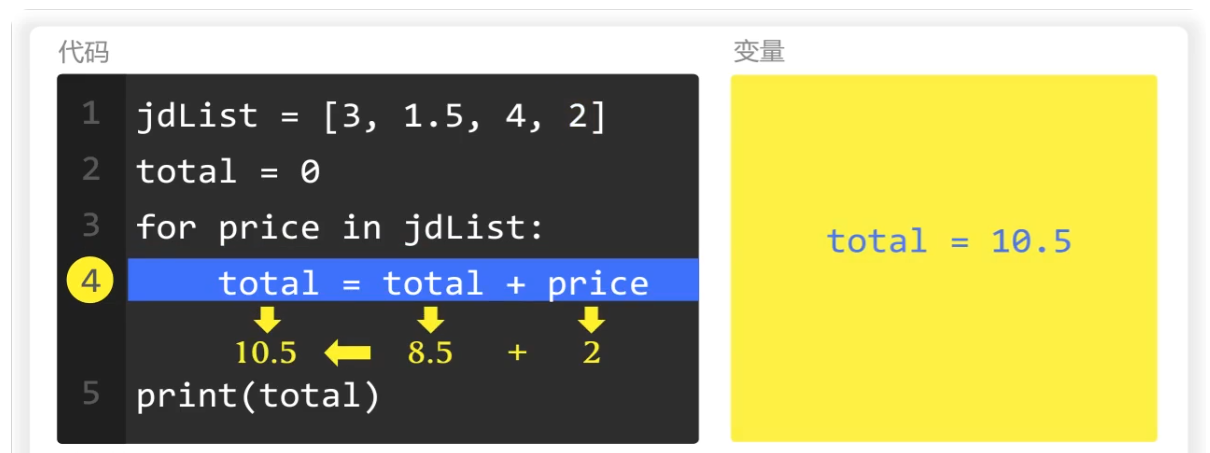
最后一次循环,price的值为2
total的值为8.5,两者相加的结果为10.5
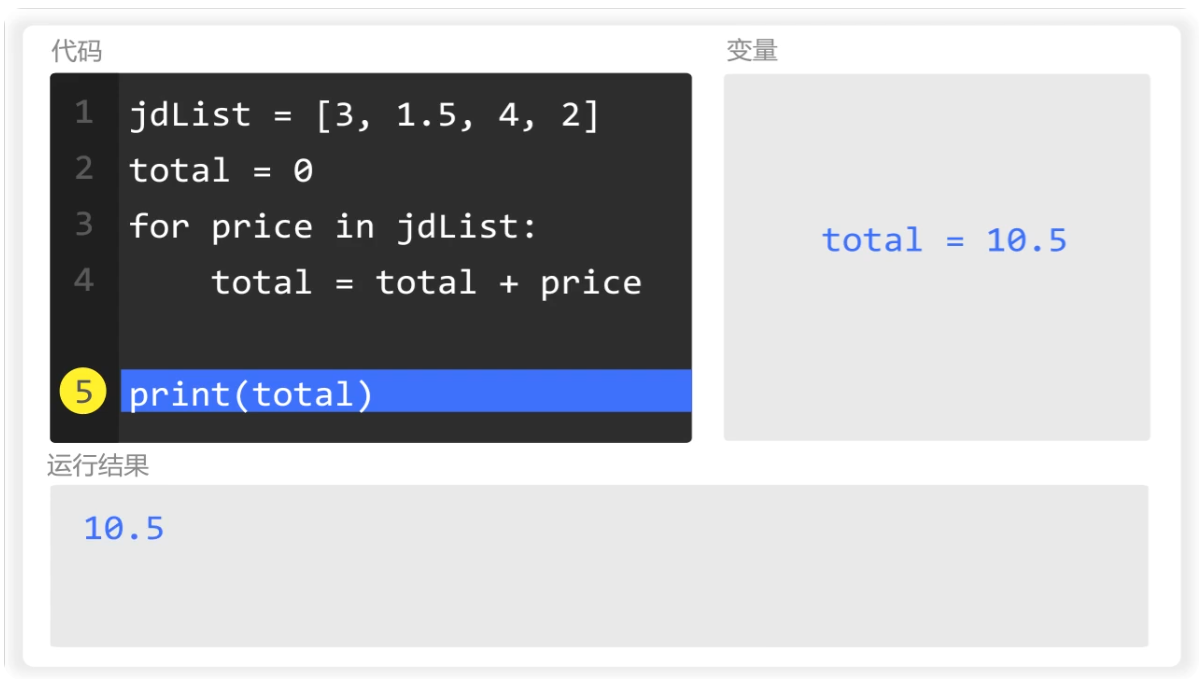
循环结束后,print输出的total就是10.5
结果
当 for 循环遍历结束后,此时,total 的值为最后一次计算的结果。
第5行,使用 print() 输出的就是列表中四个数据的总和。

代码小结
当使用累加来计算时,就需要这几部分

以上就是一个“累加”的应用演示。
但在列表的操作中,不仅有总和的计算。接下来,学习记录元素在列表中位置的方法。
计数器的应用
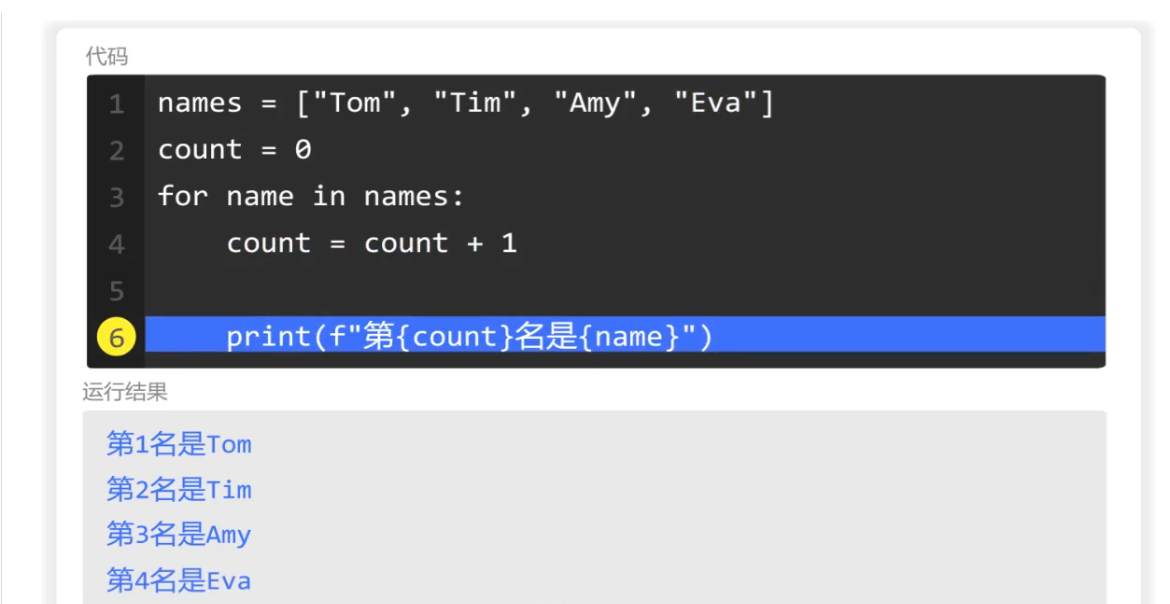
例如:班主任有一个学生名单,需要按照顺序输出,第1名是xx,第2名是xx。
一般我们会使用索引,一行行输出,点击「run」直接运行即可。
names = ["Tom", "Tim", "Amy", "Eva"]
print(f"第1名是{names[0]}")
print(f"第2名是{names[1]}")
print(f"第3名是{names[2]}")
print(f"第4名是{names[3]}")但是这样一行行的输出太繁琐了。
为了解决这个问题,可以使用“计数器”来记录当前的遍历位置。
(什么是“计数器”? “计数器”与“累加”的用法类似,在日常生活中,用来统计当前项目的进度)
因此,班主任输出学生排名,可以在遍历姓名的同时,使用“计数器”统计当前位置。

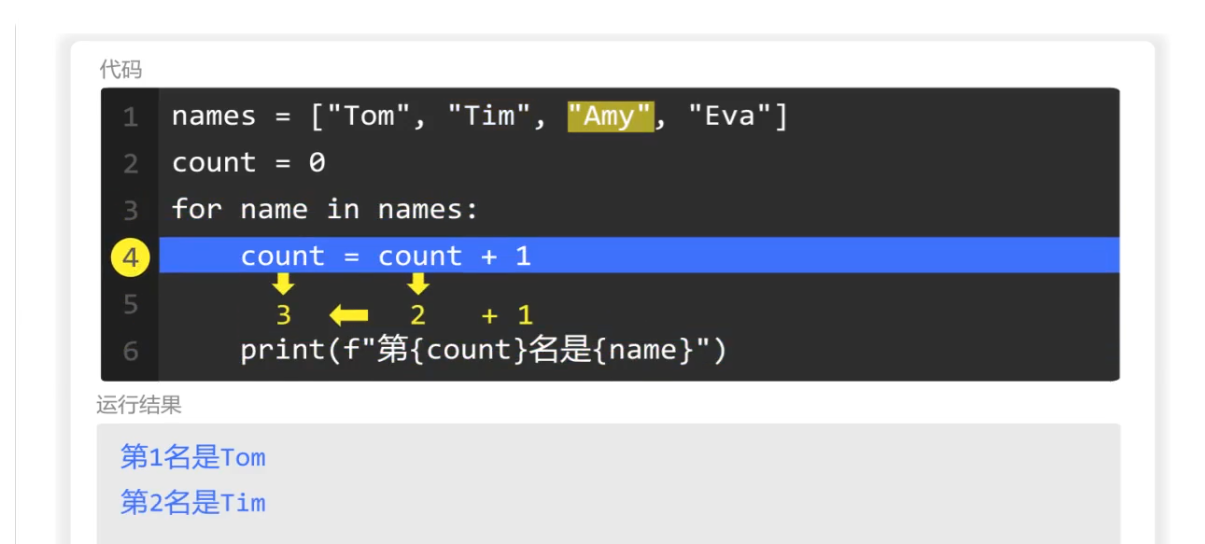
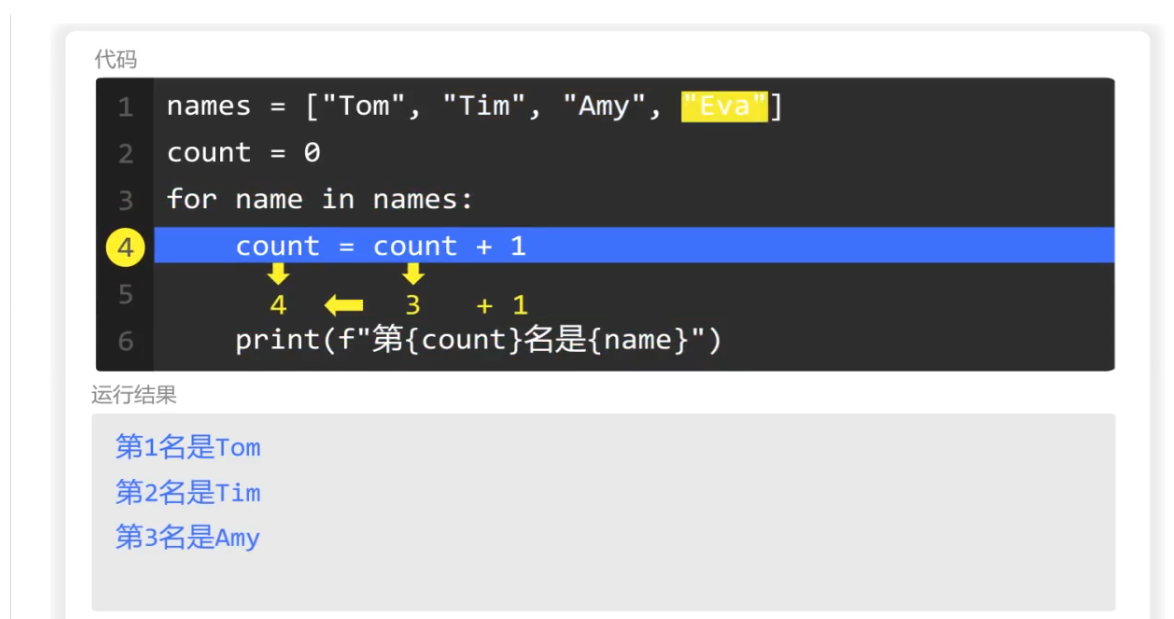
(计数器计算过程)
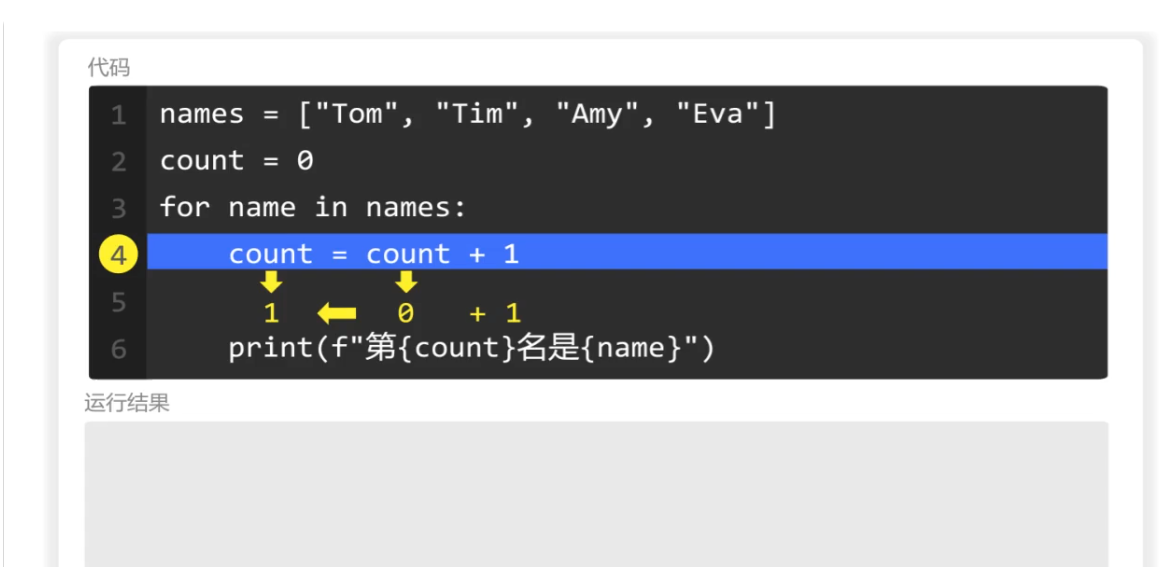
for循环第一次遍历列表,
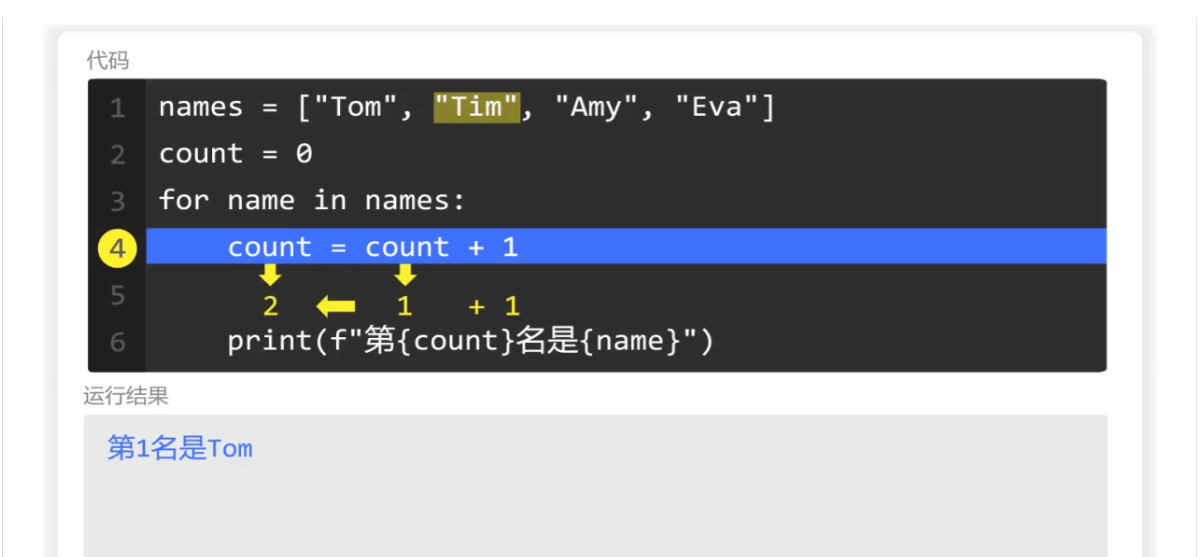
然后使用count进行计数,此时count的值为0,+1,赋值给count,于是count的值为1.
同时数出那names列表里的第一个元素是Tom,于是输出"第一名是Tom"

第二次继续遍历
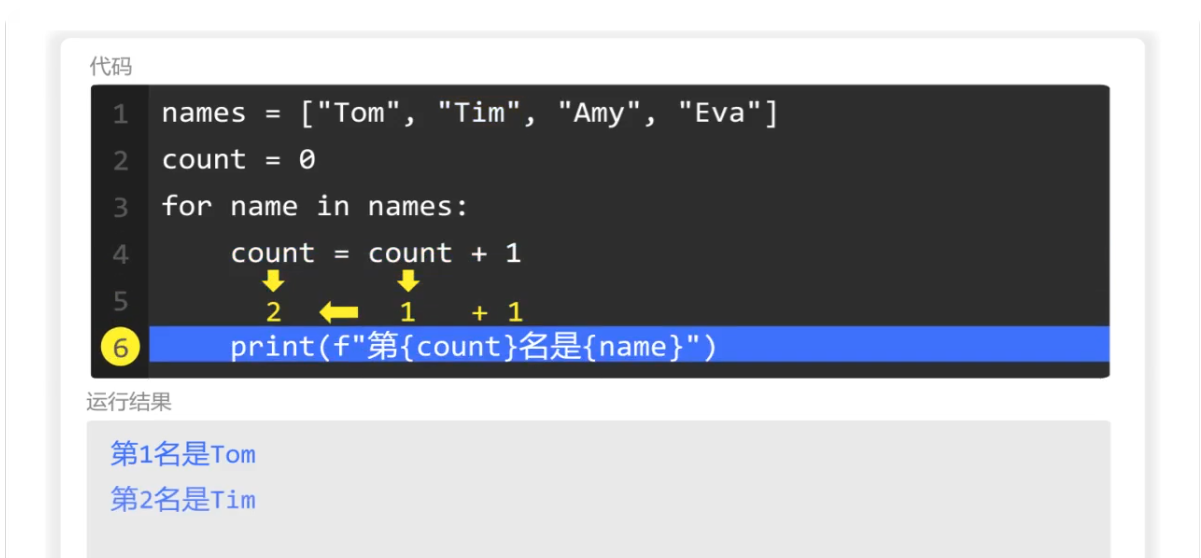
每次遍历count的值就加1

直到遍历完成。
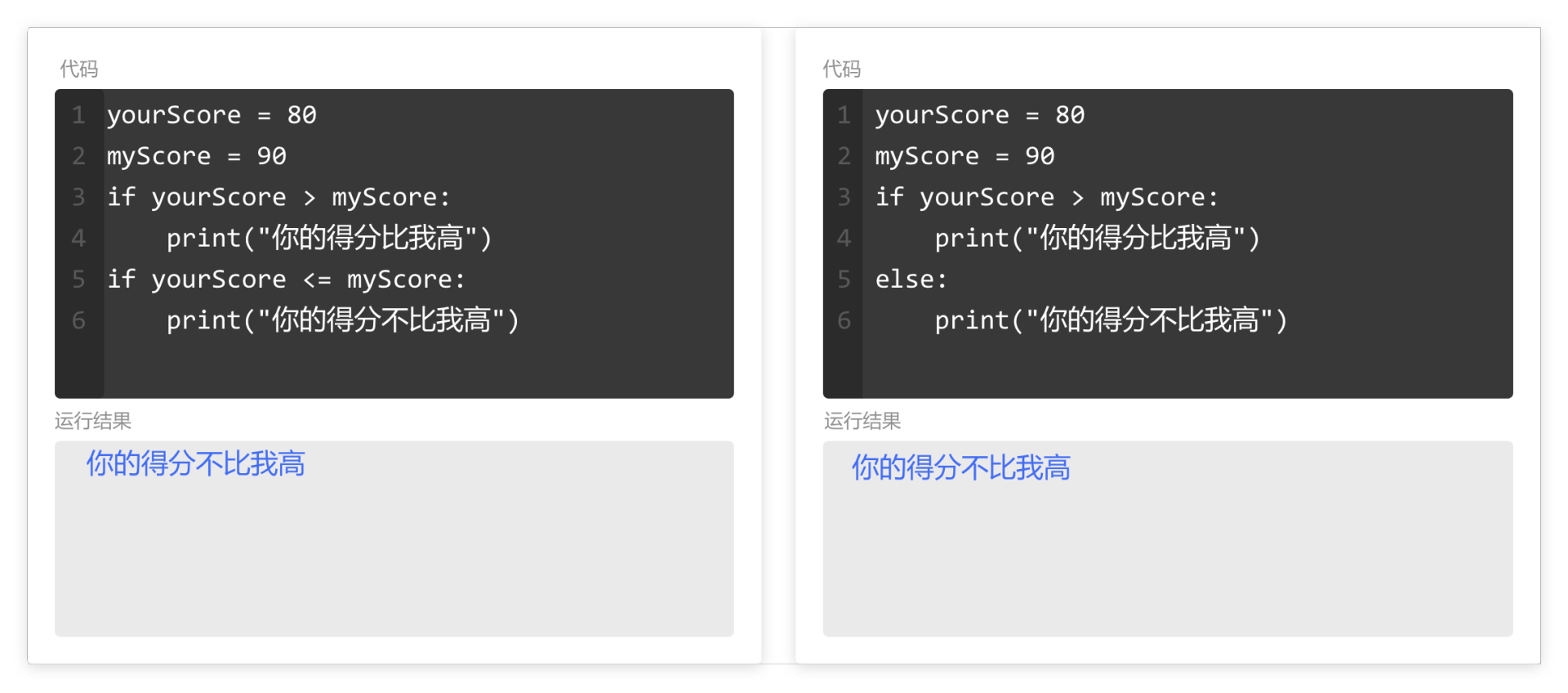
if判断的复杂应用
学习了“累加”和“计数器”的用法后,但是部分情况下,我们不一定会对列表中的每个元素都进行累加,如果只取部分,该怎么处理呢?
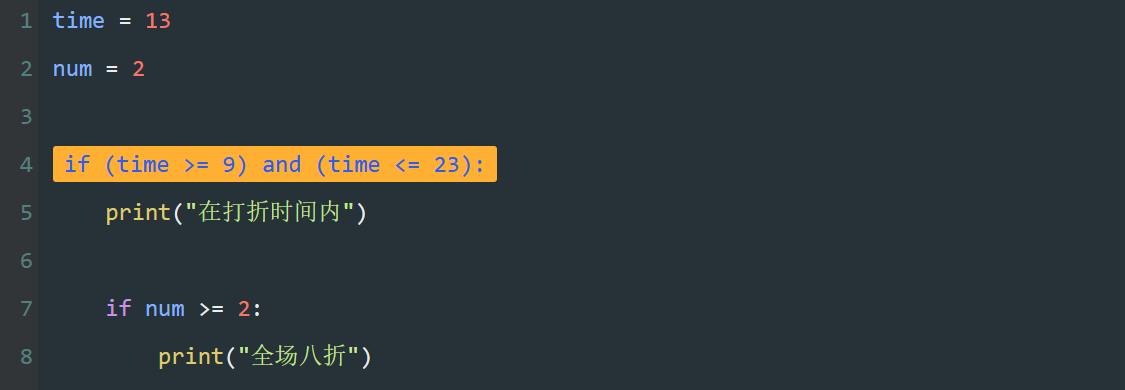
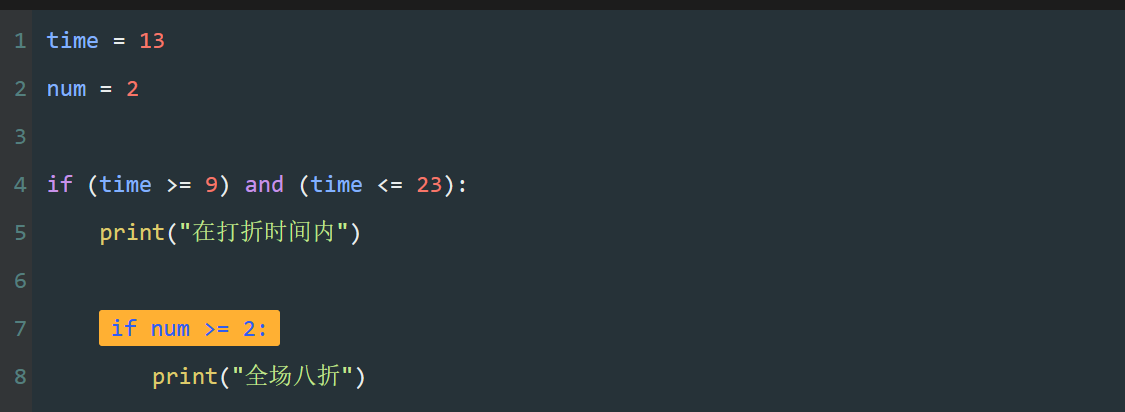
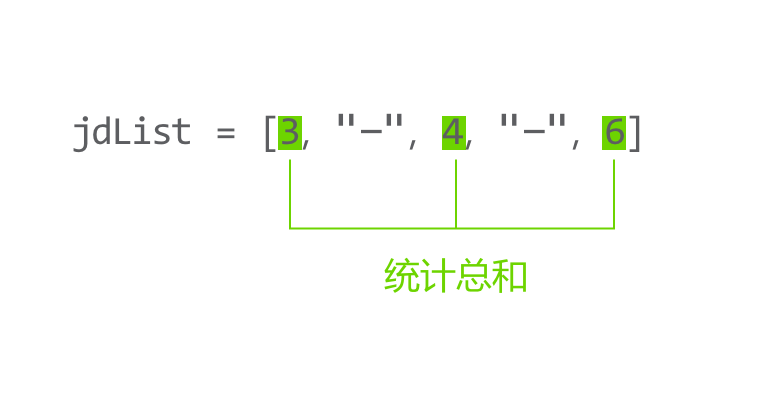
如图所示,列表中已售罄商品使用"-"表示,想要剔除"-",统计剩余商品总价,该怎样计算呢?
这时,需要使用 if 语句,先判断再计算。
如图所示,逐个取出列表中的元素,使用 if 判断,元素不等于"-"时,再进行累加。

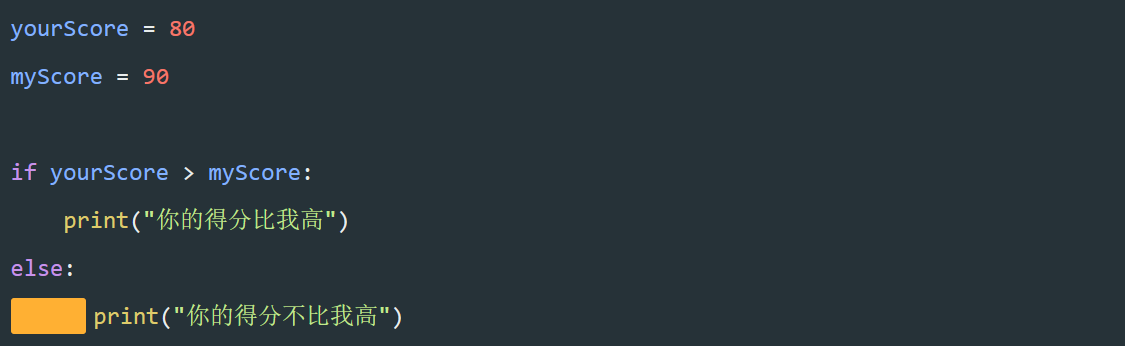
整理前面的思路,剔除"-"计算列表 jdList 的商品总价代码如图。
第4行,if 判断 price 不等于 "-" 时,使用累加计算总价。

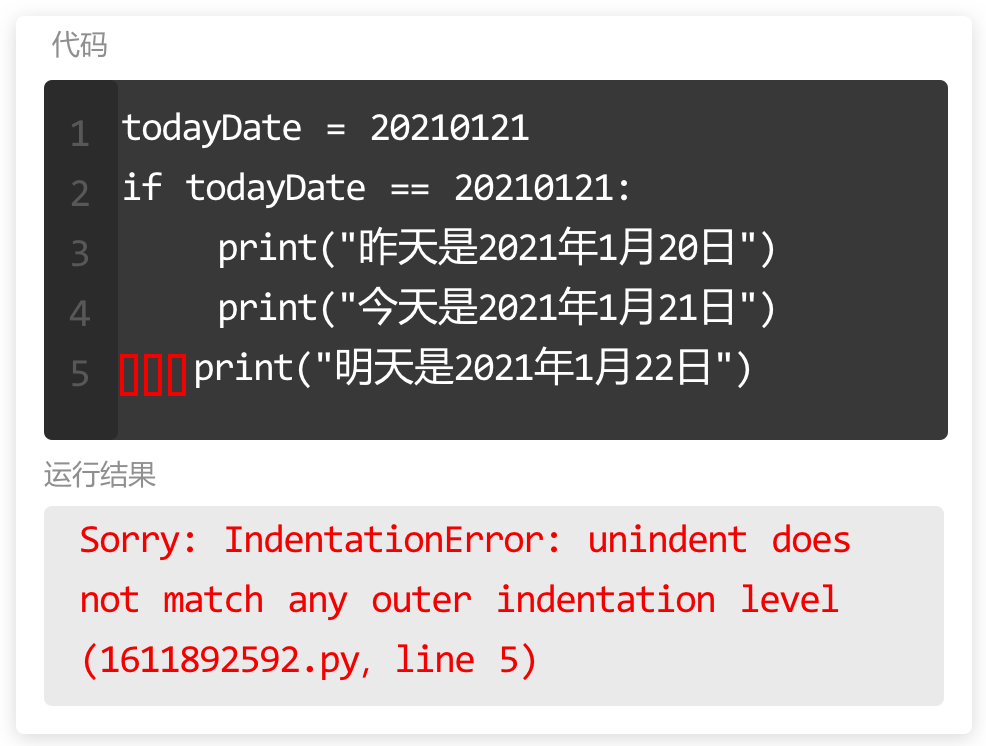
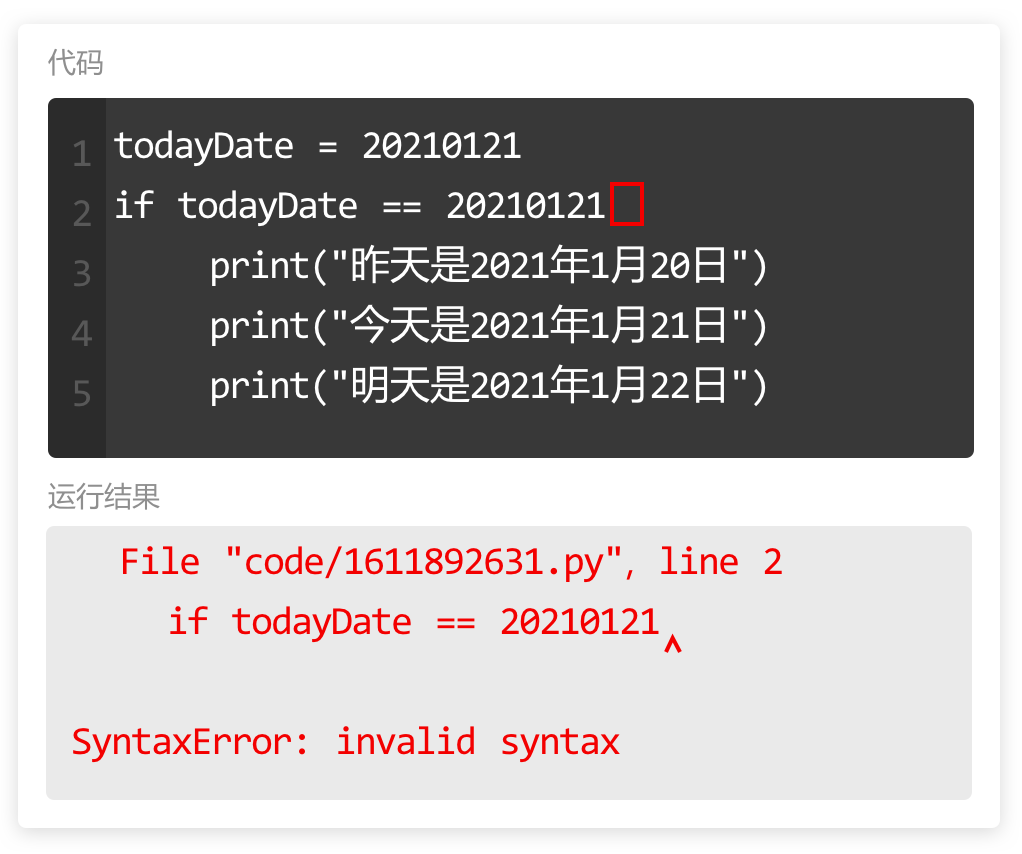
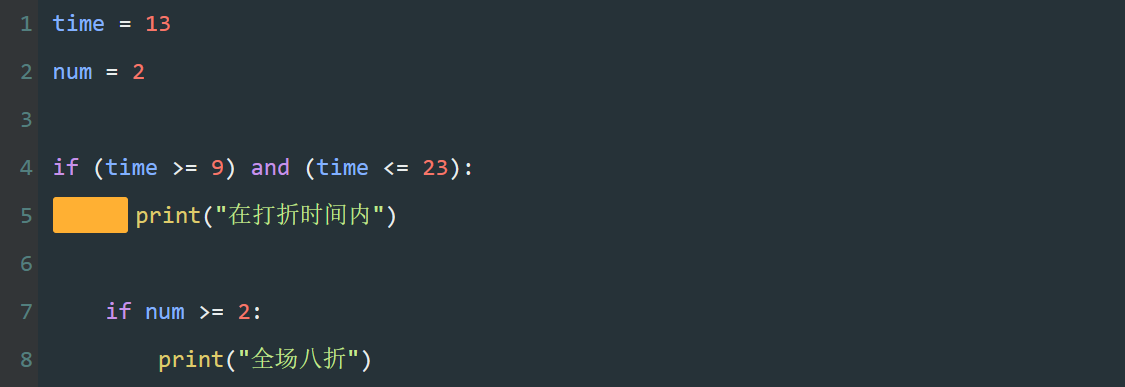
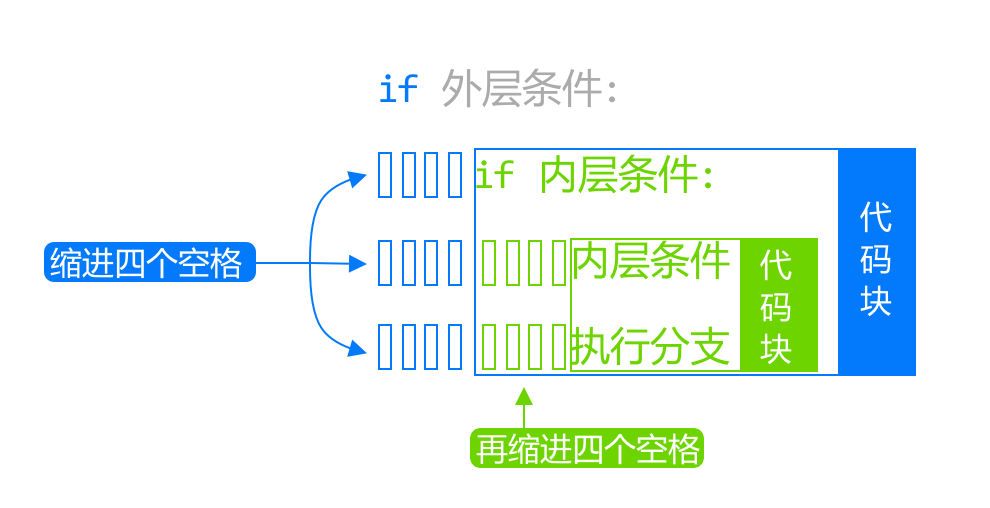
在 for 循环中使用 if 语句时,需要注意缩进。
第一个缩进,上节课学过 for 循环中的代码需要增加缩进,表明是一个代码块。
第二个缩进,使用 if 语句时,语句里面的内容也需要增加缩进。
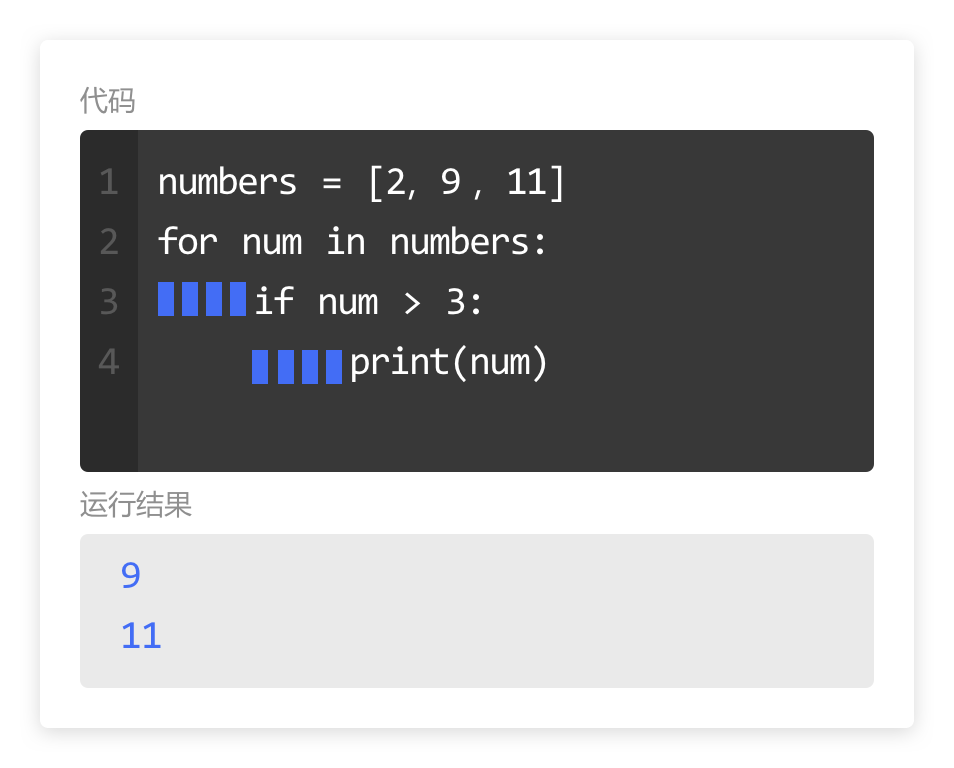
使用 for 循环和 if 语句时,需要注意 print() 的位置。
- 当 print() 在 for 循环中缩进四个空格时,按照代码执行顺序,遍历每个元素后再输出。

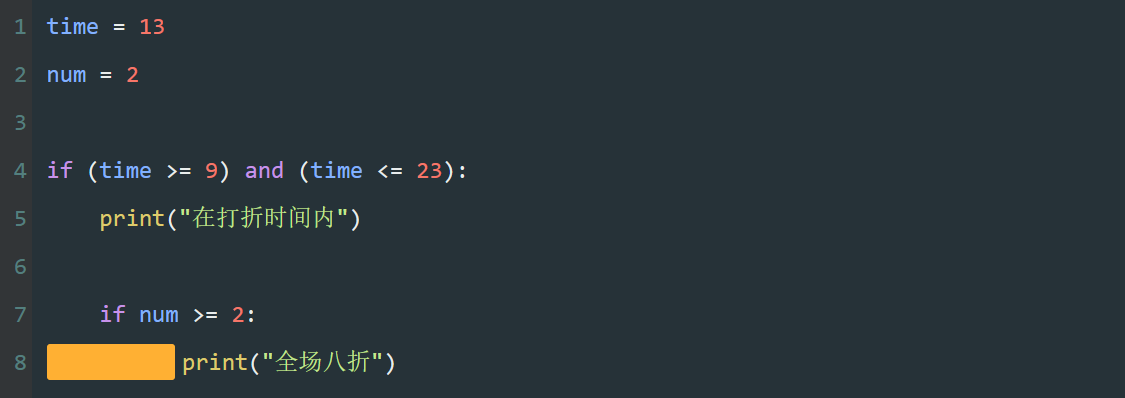
- 当 print() 位置在 if 语句的代码中时,表明 print() 是 if 代码块中的内容。
只有在 if 判断的情况成立时,才会执行 print() 。
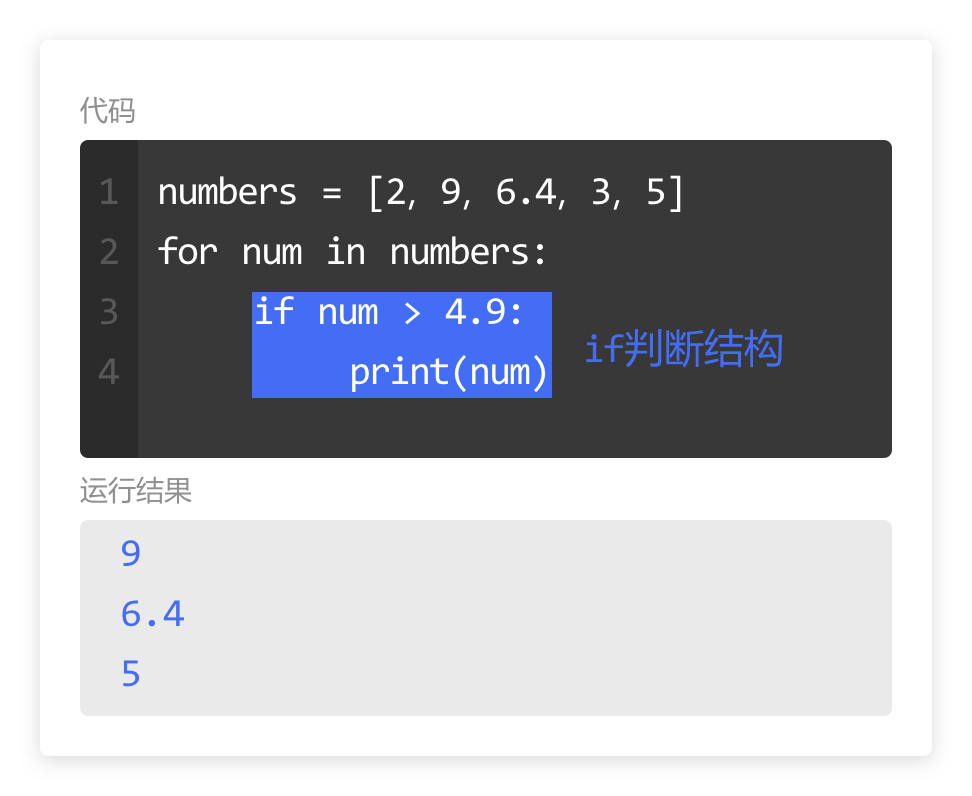
- 当 print() 位置与 if 语句缩进相同,按照代码执行的顺序,先执行 if 语句块,然后执行 print() 。
因此,这里输出的内容也是列表中所有的元素。

- 当 print() 位置与 for 循环缩进相同时,按照代码执行顺序,循环结束后,再执行 print() 语句。
因此,输出的内容为最终结果。

小练习 - 奇数的个数
要求:
定义变量 count ,初始值为0,用于计算奇数的个数;
使用 for 循环遍历列表,在循环中使用 if 语句判断,当元素为奇数时,将计数器 count 的值加一。
循环结束后,使用 print() 输出 count 。
# 定义numbers存储
numbers = [33.2, 4, 5, 7, 1, 2.8, 7, 5]
# 定义count初始值为0
count = 0
# 遍历列表,使用 if 判断num取模等于1时
# count计数加1,输出最终个数
for num in numbers:
if num % 2 == 1:
count = count + 1
print(count)小练习 - 奇数的和
要求:
定义变量 result ,初始值为0,用于存储所有奇数的和;
使用 for 循环遍历列表,在循环中使用 if 语句判断,当元素为奇数时,将元素进行累加。
循环结束后,使用 print() 输出 result 。
# 定义列表numbers
numbers = [33.2, 4, 5, 7, 1, 2.8, 7, 5]
# 定义变量result,初始值为0
result = 0
# for循环遍历列表
for num in numbers:
# 使用if判断,num取模的值等于1时
if num % 2 == 1:
# result和num相加,赋值给result
result = result + num
# 使用print()输出结果
print(result)