Django DTL 模板
目前市面上有非常多的模板系统,其中最知名最好用的就是DTL和Jinja2。 DTL 是 Django Template Language 三个单词的缩写,也就是Django自带的模板语言。当然也可以配置Django支持Jinja2等其他模板引擎,但是作为Django内置的模板语言,和Django可以达到无缝衔接而不会产生一些不兼容的情况。
DTL与普通的HTML文件的区别
DTL模板是一种带有特殊语法的HTML文件,这个HTML文件可以被Django编译,可以传递参数进去,实现数据动态化。在编译完成后,生成一个普通的HTML文件,然后发送给客户端。
渲染模板
渲染模板有多种方式。列举两种常用的方式。
render_to_string :找到模板,然后将模板编译后渲染成Python的字符串格式。最后再通过HttpResponse 类包装成一个 HttpResponse 对象返回回去。示例代码如下:
from django.template.loader import render_to_string
from django.http import HttpResponse
def book_detail(request,book_id):
html = render_to_string("detail.html")
return HttpResponse(html)django还提供了一个更加简便的方式,直接将模板渲染成字符串和包装成 HttpResponse 对象一步到位完成。示例代码如下:
from django.shortcuts import render
def book_list(request):
return render(request,'list.html')模板查找路径配置:
在项目的 settings.py 文件中。有一个 TEMPLATES 配置,这个配置包含了模板引擎的配置,模板查找路径的配置,模板上下文的配置等。
模板路径可以在两个地方配置。
DIRS :这是一个列表,在这个列表中可以存放所有的模板路径,以后在视图中使用 render 或者render_to_string 渲染模板的时候,会在这个列表的路径中查找模板。
APP_DIRS :默认为 True ,这个设置为 True 后,会在 INSTALLED_APPS 的安装了的 APP 下的templates 文件夹中查找模板。
TEMPLATES = [
{
....
# 定义存放模板的目录,这里使用 templates 目录
"DIRS": [BASE_DIR / "templates"],
"APP_DIRS": True,
"OPTIONS": {
...
},
]
查找顺序:比如代码 render('list.html') 。先会在 DIRS 这个列表中依次查找路径下有没有这个模板,如果有,就返回。
如果 DIRS 列表中所有的路径都没有找到,那么会先检查当前这个视图所处的 app 是否已经安装,如果已经安装了,那么就先在当前这个 app 下的 templates 文件夹中查找模板,如果没有找到,那么会在其他已经安装了的 app 中查找。如果所有路径下都没有找到,那么会抛出一个 TemplateDoesNotExist 的异常。
DTL模板语法
变量:
模板中可以包含变量, Django 在渲染模板的时候,可以传递变量对应的值过去进行替换。变量的命名规范和 Python 非常类似,只能是阿拉伯数字和英文字符以及下划线的组合,不能出现标点符号等特殊字符。
变量需要通过视图函数渲染,视图函数在使用 render 或者 render_to_string 的时候可以传递一个context 的参数,这个参数是一个字典类型。以后在模板中的变量就从这个字典中读取值的。示例代码如下:
# views.py代码
def profile(request):
return render(request,'profile.html',context={'username':'陌上花'})
# profile.html模板代码
<p>{{ username }}</p>
除了变量,还可以是字典,列表以及对象。模板中的变量同样也支持 点(.) 的形式。
# views.py代码
def info(request):
# 1. 普通的变量
username = "悦来小陌"
# 2. 字典类型
book = {"firm": "悦来集团", "name": "henry"}
# 3. 列表
books = [
{"name": "全职高手", "author": "蝴蝶蓝"},
{"name": "斗破苍穹", "author": "天蚕土豆"},
]
# 4. 对象
class Person:
def __init__(self, realname):
self.realname = realname
context = {
"username": username,
"book": book,
"books": books,
"Person": Person("陌上花"),
}
return render(request, "info.html", context=context)
# infp.html模板代码
<!-- 变量 -->
<p>{{username}}</p>
<!-- 字典 -->
<p>公司名称:{{book.firm}}, CEO: {{book.name}}</p>
<!-- 列表 -->
<p>下标为 0 的小说作者是: {{books.0.author}}</p>
<p>下标为 1 的小说是: {{books.1.name}}</p>
<!-- 对象 -->
<p>姓名为: {{Person.realname}}</p>
在出现了点的情况,比如book.firm ,模板是按照以下方式进行解析的:
- 如果
book是一个字典,那么就会查找这个字典的firm这个key对应的值。 - 如果
person是一个对象,那么就会查找这个对象的realname属性,或者是realname这个方法。 - 如果出现的是
books.1,会判断books是否是一个列表或者元组或者任意的可以通过下标访问的对象,如果是的话就取这个列表的第1个值。如果不是就获取到的是一个空的字符串。
有以下几点需要注意:
- 不能通过中括号的形式访问字典和列表中的值,比如
dict['key']和list[1]是不支持的!DTL模板语法里改为点(.)来访问,对应的应该是dict.key和list.1 - 因为使用点(
.)语法获取对象值的时候,可以获取这个对象的属性,如果这个对象是一个字典,也可以获取这个字典的值。所以在给这个字典添加key的时候,千万不能和字典中的一些属性重复。比如items,因为items是字典的方法,那么如果给这个字典添加一个items作为key,那么以后就不能再通过item来访问这个字典的键值对了。
常用的模板标签
if 标签
if 标签相当于 Python 中的 if 语句,有 elif 和 else 相对应,但是所有的标签都需要用标签符号( {%%} )进行包裹。
if 标签中可以使用 ==、!=、<、<=、>、>=、in、not in、is、is not 等判断运算符。
还有注意的是,使用if时有起始标签{% if %},就要有结束标签{% endif %}
{% if num > 18 %}
<p>数字大于 18</p>
{% elif num == 18 %}
<p>数字等于 18</p>
{% else %}
<p>数字小于 18</p>
{% endif %}for...in... 标签
for...in... 类似于 Python 中的 for...in... 。可以遍历列表、元组、字符串、字典等一切可以遍历的对象。
{% for person in persons %}
<p>{{ person.name }}</p>
{% endfor %}如果想要反向遍历,那么在遍历的时候就加上一个 reversed 。
{% for person in persons reversed %}
<p>{{ person.name }}</p>
{% endfor %}遍历字典的时候,需要使用 items 、 keys 和 values 等方法。在 DTL 中,执行一个方法不能使用圆括号的形式。遍历字典示例代码如下:
{% for key,value in person.items %}
<p>key:{{ key }}</p>
<p>value:{{ value }}</p>
{% endfor %}在 for 循环中, DTL 提供了一些变量可供使用。这些变量如下:
forloop.counter :当前循环的下标。以1作为起始值。
forloop.counter0 :当前循环的下标。以0作为起始值。
forloop.revcounter :当前循环的反向下标值。比如列表有5个元素,那么第一次遍历这个属性是等于5,第二次是4,以此类推。并且是以1作为最后一个元素的下标。
forloop.revcounter0 :类似于 forloop.revcounter 。不同的是最后一个元素的下标是从0开始。
forloop.first :是否是第一次遍历。
forloop.last :是否是最后一次遍历。
forloop.parentloop :如果有多个循环嵌套,那么这个属性代表的是上一级的for循环。
for...in...empty 标签
这个标签使用跟 for...in... 是一样的,只不过是在遍历的对象如果没有元素的情况下,会执行 empty 中的内容。
{% for person in persons %}
<li>{{ person }}</li>
{% empty %}
暂时还没有任何人
{% endfor %}with 标签
在模版中定义变量。有时候一个变量访问的时候比较复杂,那么可以先把这个复杂的变量缓存到一个变量上,以后就可以直接使用这个变量就可以了。
context = {
"persons": ["xiaomo","henry"]
}
{% with lisi=persons.1 %}
<p>{{ lisi }}</p>
{% endwith %}有几点需要强烈的注意:
在 with 语句中定义的变量,只能在 {%with%}{%endwith%} 中使用,不能在这个标签外面使用。
定义变量的时候,不能在等号左右两边留有空格。比如 {% with lisi = persons.1%} 是错误的。
还有另外一种写法同样也是支持的:
{% with persons.1 as lisi %}
<p>{{ lisi }}</p>
{% endwith %}url 标签
在模版中,经常要写一些 url ,比如某个a标签中需要定义 href 属性。当然如果通过硬编码的方式直接将这个 url 写死在里面也是可以的。但是这样对于以后项目维护可能不是一件好事。
因此建议使用这种反转的方式来实现,类似于 django 中的 reverse 一样。
<a href="{% url 'book:list' %}">图书列表页面</a>如果 url 反转的时候需要传递参数,那么可以在后面传递。但是参数分位置参数和关键字参数。位置参数和关键字参数不能同时使用。
# path部分
path('detail/<book_id>/',views.book_detail,name='detail')
# url反转,使用位置参数
<a href="{% url 'book:detail' 1 %}">图书详情页面</a>
# url反转,使用关键字参数
<a href="{% url 'book:detail' book_id=1 %}">图书详情页面</a>spaceless 标签
移除html标签中的空白字符。包括空格、tab键、换行等。
{% spaceless %}
<p>
<a href="foo/">Foo</a>
</p>
{% endspaceless %}那么在渲染完成后,会变成以下的代码:
<p><a href="foo/">Foo</a></p>aceless 只会移除html标签之间的空白字符。而不会移除标签与文本之间的空白字符。
autoescape 标签
开启和关闭这个标签内元素的自动转义功能。自动转义是可以将一些特殊的字符。比如<转义成 html 语法能识别的字符,会被转义成<,而>会被自动转义成 >。模板中默认是已经开启了自动转义的。
# 传递的上下文信息
context = {
"info":"<a href='www.baidu.com'>百度</a>"
}
# 模板中关闭自动转义
{% autoescape off %}
{{ info }}
{% endautoescape %}那么就会显示百度的一个超链接。如果把 off 改成 on ,那么就会显示成一个普通的字符串。
{% autoescape on %}
{{ info }}
{% endautoescape %}更多标签可以查看官方文档:https://docs.djangoproject.com/zh-hans/5.0/ref/templates/builtins/
模板常用过滤器
在模版中,有时候需要对一些数据进行处理以后才能使用,一般在 Python 中是通过函数的形式来完成的。
而在模版中,则是通过过滤器来实现的,过滤器使用的是|来使用。
比如使用 add 过滤器,那么示例代码如下:
{{ value|add:"2" }}开发中常用的过滤器
cut
移除值中所有指定的字符串。类似于 python 中的 replace(args,"") ,语法:
{{ value|cut:" " }}示例
# 数据
greet = "Hello World, Hello Python, Hello Django"
# 模板
{{greet}}
> Hello World, Hello Python, Hello Django
# 移除空格
{{greet|cut:" "}}
> HelloWorld,HelloPython,HelloDjango
# 移除逗号
{{greet|cut:","}}
>Hello World Hello Python Hello Django
date
将一个日期按照指定的格式,格式化成字符串。示例代码如下:
# 数据
context = {
"birthday": datetime.now()
}
# 模版
{{ birthday|date:"Y/m/d" }}那么将会输出 2024/07/27 。其中Y代表的是四位数字的年份,m代表的是两位数字的月份,d代表的是两位数字的日。
还有更多时间格式化的方式。见下表。
Y:四位数字的年份 (2024)
m :两位数字的月份(01-12)
n :月份,1-9前面没有0前缀(1-12)
d :两位数字的天(01-31)
j :天,但是1-9前面没有0前缀(1-31)
g :小时,12小时格式的,1-9前面没有0前缀(1-12)
h :小时,12小时格式的,1-9前面有0前缀(01-12)
G :小时,24小时格式的,1-9前面没有0前缀(1-23)
H :小时,24小时格式的,1-9前面有0前缀(01-23)
i :分钟,1-9前面有0前缀(00-59)
s :秒,1-9前面有0前缀(00-59)
default
如果值被评估为 False 。比如 [] , "" , None , {} 等这些在 if 判断中为 False 的值,都会使用default 过滤器提供的默认值。
语法
{{ value|default:"nothing" }}如果 value 是等于一个空的字符串。比如 ""
# 数据
context = {
"profile": "",
}
# 空字符就不会显示
{{profile_none}}
# 由于是空字符,就会显示 default里定义的文字 这个家伙很懒,什么都没留下.
{{profile_none|default:"这个家伙很懒,什么都没留下."}}
default_if_none
如果值是 None ,那么将会使用 default_if_none 提供的默认值。
这个和 default 有区别, default 是所有被评估为 False 的都会使用默认值。
而 default_if_none 则只有这个值是等于 None 的时候才会使用默认值。
{{ value|default_if_none:"nothing" }}如果 value 是等于 "" 也即空字符串,那么以上会输出空字符串。
如果 value 是一个 None 值,才会输出 nothing 。
first
返回列表/元组/字符串中的第一个元素。
{{ value|first }}如果 value 是等于 ['a','b','c'] ,那么输出将会是a
last
返回列表/元组/字符串中的最后一个元素。
{{ value|last }}如果 value 是等于 ['a','b','c'] ,那么输出将会是c
floatformat
使用四舍五入的方式格式化一个浮点类型。
如果这个过滤器没有传递任何参数,那么只会在小数点后保留一个小数。
如果小数后面全是0,那么只会保留整数。也可以传递一个参数,标识具体要保留几个小数。
# 数据
context = {
"num": [34.45678, 18.000, 5.17],
}
不传参数:{{num.0|floatformat}}
>不传参数:34.5
传参数保留3位:{{num.0|floatformat:3}}
>传参数保留3位:34.457
join
类似与 Python 中的 join ,将列表/元组/字符串用指定的字符进行拼接。
{{ value|join:"/" }}如果 value 是等于 ['a','b','c'] ,那么以上代码将输出 a/b/c 。
length
获取一个列表/元组/字符串/字典的长度。
{{ value|length }}如果 value 是等于 ['a','b','c'] ,那么以上代码将输出3
如果 value 为 None ,那么以上将返回0
random
在被给的列表/字符串/元组中随机的选择一个值。
{{ value|random }}如果 value 是等于 ['a','b','c'] ,那么以上代码会在列表中随机选择一个
safe
标记一个字符串是安全的。也即会关掉这个字符串的自动转义。
{{value|safe}}如果 value 是一个不包含任何特殊字符的字符串,比如 <a> 这种,那么以上代码就会把字符串正常的输入。
如果 value 是一串 html 代码,那么以上代码将会把这个 html 代码渲染到浏览器中。
# 数据
context = {
"html": "<h2>欢迎来到悦来集团!</h2>",
}
# 只会原封不动的带标签渲染显示出来
{{html}}
><h2>欢迎来到悦来集团!</h2>
# 会解析标签的作用,然后渲染显示
{{html|safe}}
>欢迎来到悦来集团!slice
类似于 Python 中的切片操作
{{ some_list|slice:"2:" }}将会给 some_list 从2开始做切片操作
stringtags
删除字符串中所有的 html 标签
{{ value|striptags }}如果 value 是 <strong>hello world</strong> ,那么以上代码将会输出 hello world 。
truncatechars
如果给定的字符串长度超过了过滤器指定的长度。那么就会进行切割,并且会拼接三个点来作为省略号。
{{ value|truncatechars:5 }}如果 value 是等于 abcdef ,那么输出的结果是 abcd… ,只有四个字母是因为三个点也占了一个字符
模版结构
include模版
有时候一些代码是在许多模版中都用到的。如果每次都重复的去拷贝代码那肯定不符合项目的规范。
一般可以把这些重复性的代码抽取出来,就类似于Python中的函数一样,以后想要使用这些代码的时候,就通过 include 包含进来。这个标签就是 include 。
# header.html
<p>我是header</p>
# footer.html
<p>我是footer</p>
# main.html
{% include 'header.html' %}
<p>我是main内容</p>
{% include 'footer.html' %}include 标签寻找路径的方式。也是跟 render 渲染模板的函数是一样的。
默认 include 标签包含模版,会自动的使用主模版中的上下文,也即可以自动的使用主模版中的变量。
模板继承
在前端页面开发中。有些代码是需要重复使用的。
这种情况可以使用 include 标签来实现,也可以使用另外一个比较强大的方式来实现,那就是模版继承。
模版继承类似于 Python 中的类,在父类中可以先定义好一些变量和方法,然后在子类中实现。
模版继承也可以在父模版中先定义好一些子模版需要用到的代码,然后子模版直接继承就可以了。并且因为子模版肯定有自己的不同代码,因此可以在父模版中定义一个block接口,然后子模版再去实现。
以下是父模版的代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>{% block title %}{% endblock %} - 陌上花</title>
{% block head %}{% endblock %}
</head>
<body>
<hender>
<ul>
<li><a href="/">首页</a></li>
<li><a href="/">留言</a></li>
</ul>
</hender>
{% block body %}{% endblock %}
<footer>Copyright © Blog All Rights Reserved. 2016-</footer>
</body>
</html>
这个模版,取名叫做 base.html ,定义好一个简单的 html 骨架。
然后定义好 block 接口,让子模版来根据具体需求来实现。
block 接口的定义和模板标签一样,需要有起始标签{% block 自定义名称 %},就要有结束标签 {% endblock %}
hotarticle.html文件的内容
<div>
<h2>热门文章</h2>
<ul>
<li>文章</li>
<li>文章</li>
<li>文章</li>
<li>文章</li>
{% for article in articles %}
<li>{{article}}</li>
{% endfor%}
</ul>
</div>子模板然后通过 extends 标签来实现,示例代码如下:
{% extends "cc_base.html" %}
{% block title %}首页{% endblock %}
{% block head %}
<style>
body {background-color: pink;}
</style>
{% endblock %}
{% block body %}
{% include "hotarticle.html"%}
{% endblock%}以上代码保存后解析的代码会成这样,框起来的地方就是三个 block 传入的数据
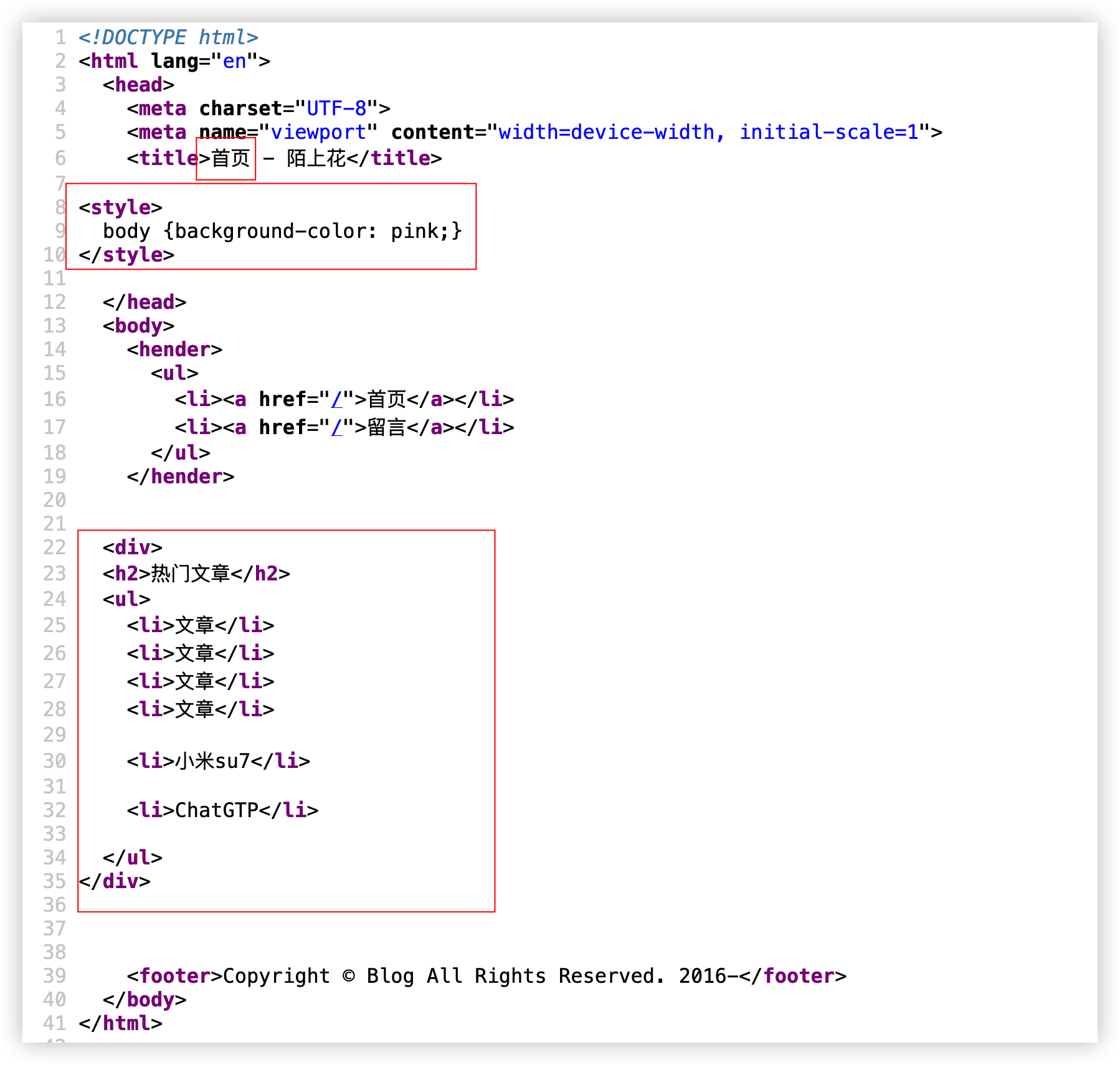
具体效果
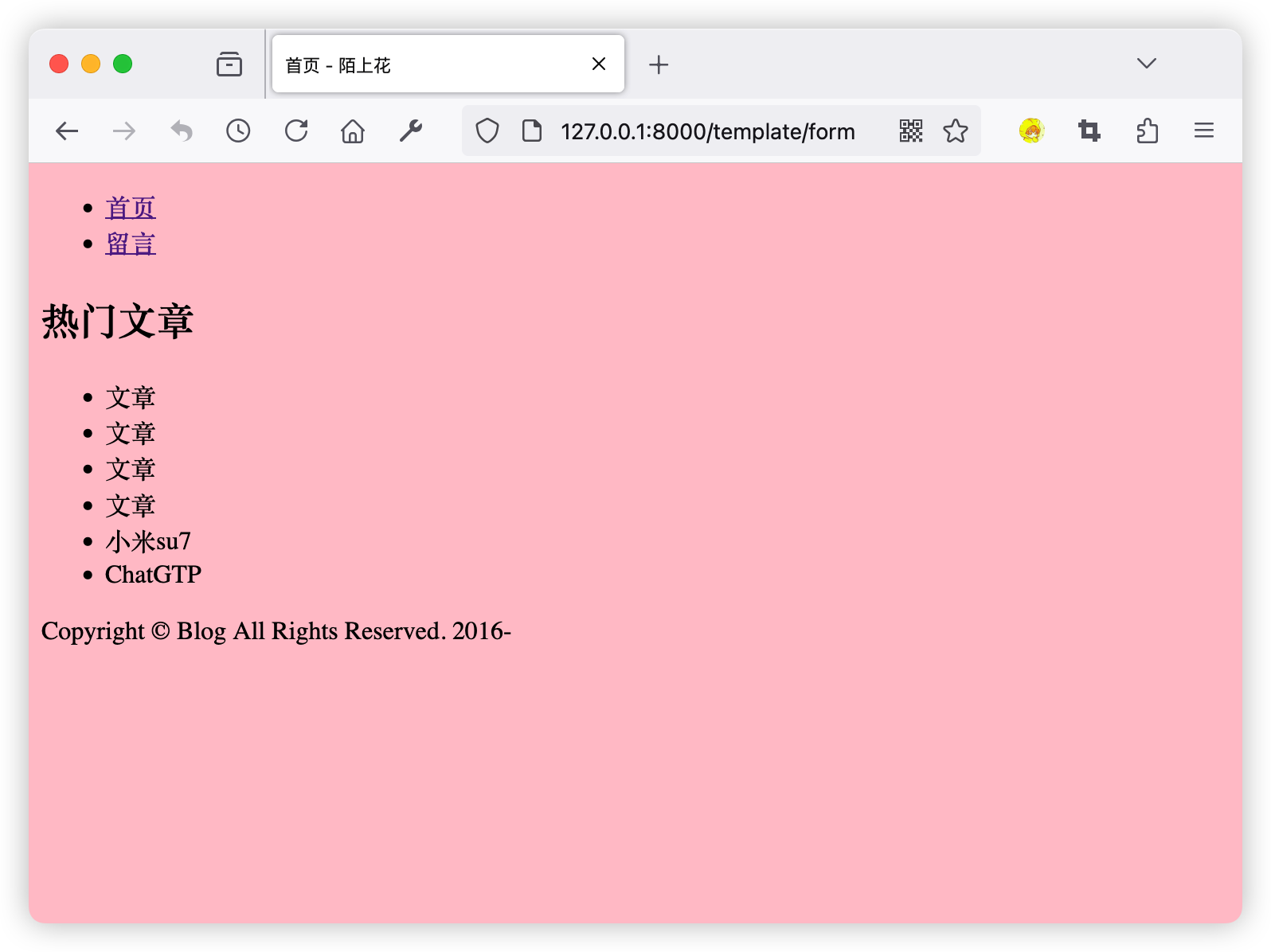
需要注意的是:extends标签必须放在模版的第一行。子模板中的代码必须放在block中,否则将不会被渲染。
如果在某个 block 中需要使用父模版的内容,那么可以使用 {{block.super}} 来继承。比如上例,{%block title%} ,如果想要使用父模版的 title ,那么可以在子模版的 title block 中使用 {{ block.super }} 来实现。
在定义 block 的时候,除了在 block 开始的地方定义这个 block 的名字,还可以在 block 结束的时候定义名字。比如 {% block title %}{% endblock title %} 。这在大型模版中显得尤其有用,能让你快速的看到 block 包含在哪里。