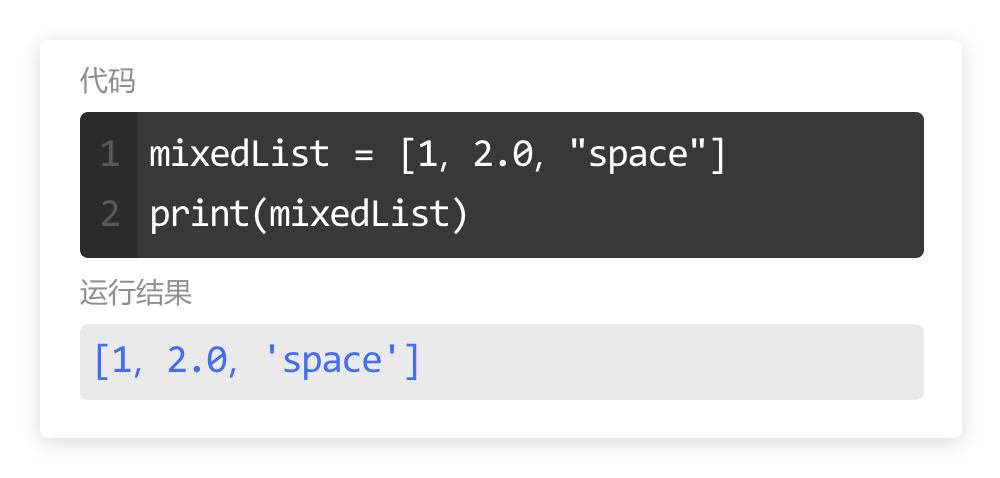
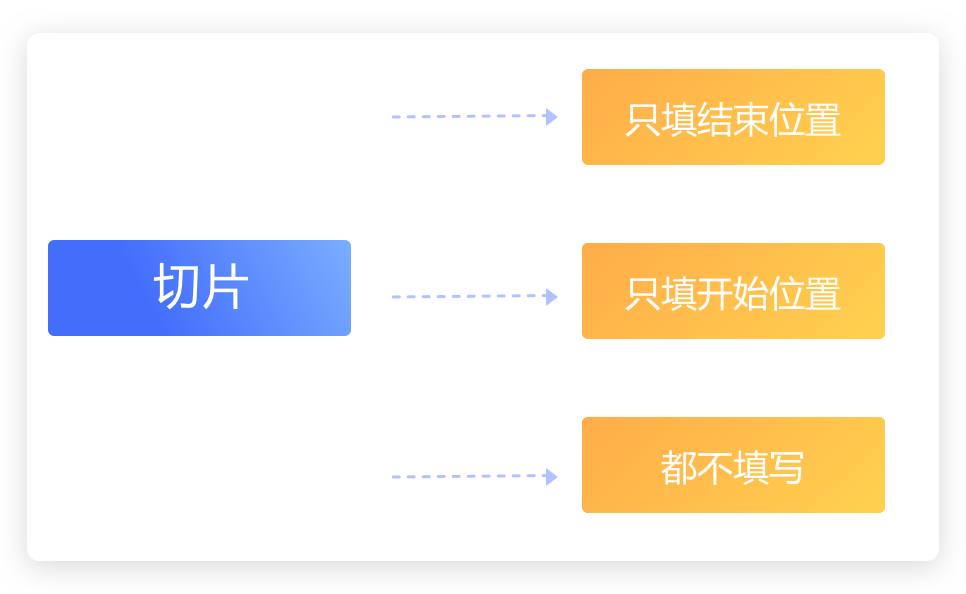
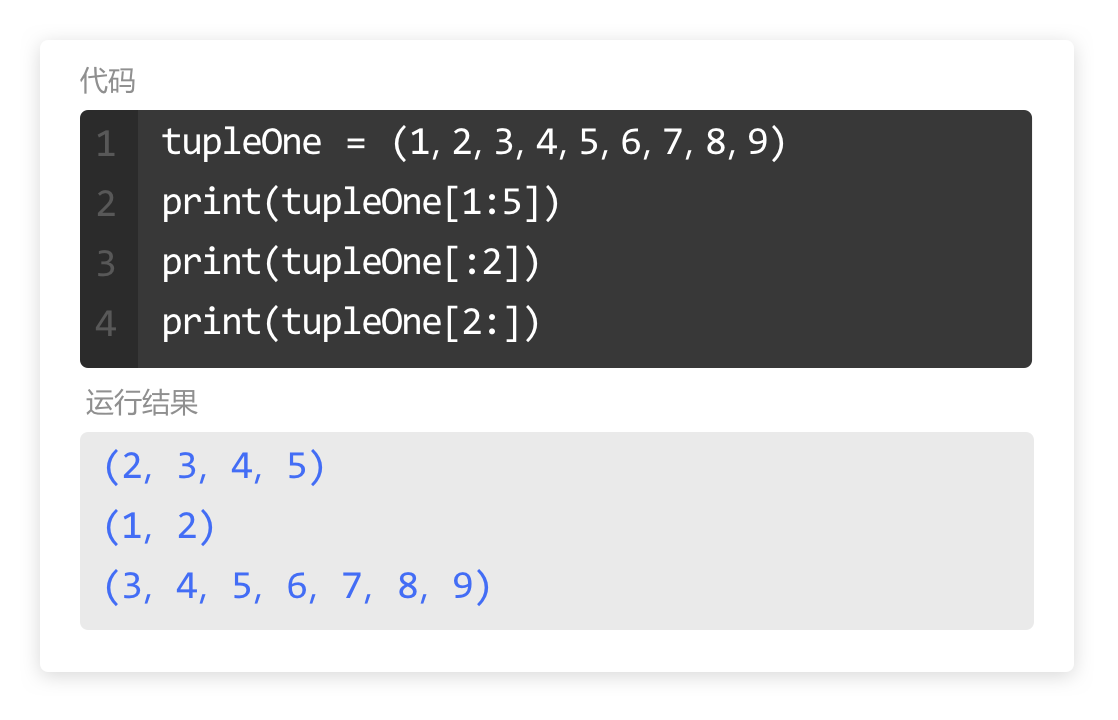
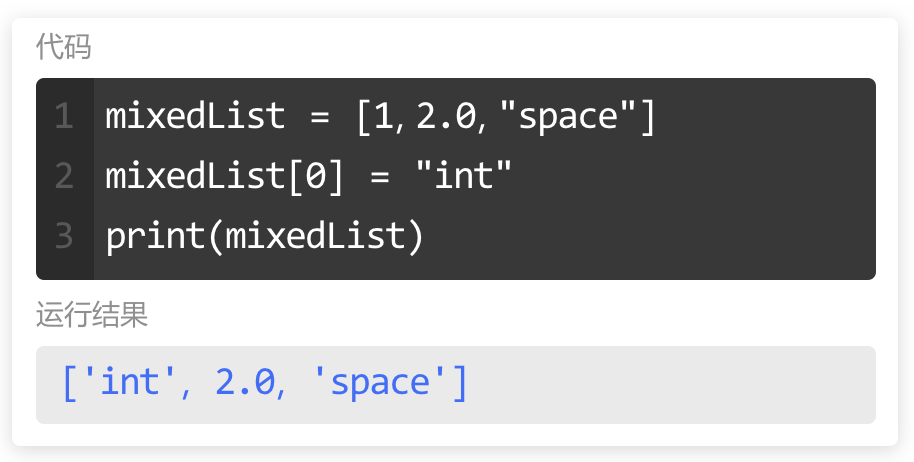
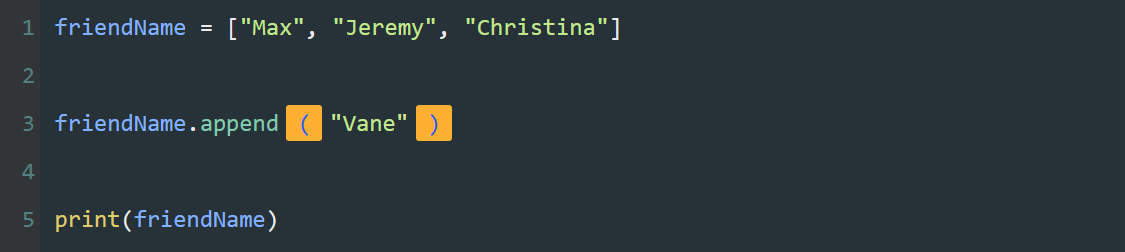
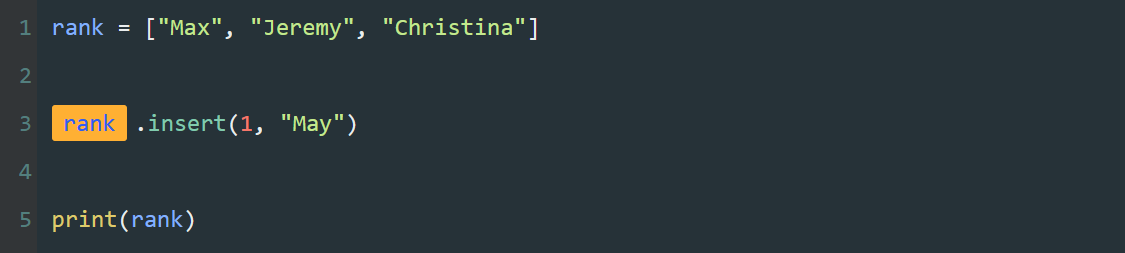
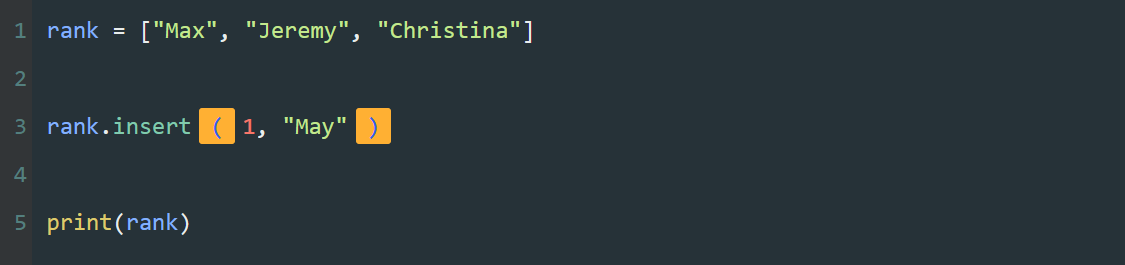
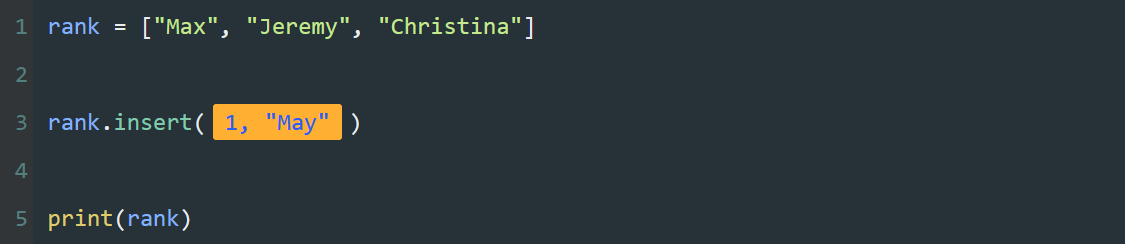
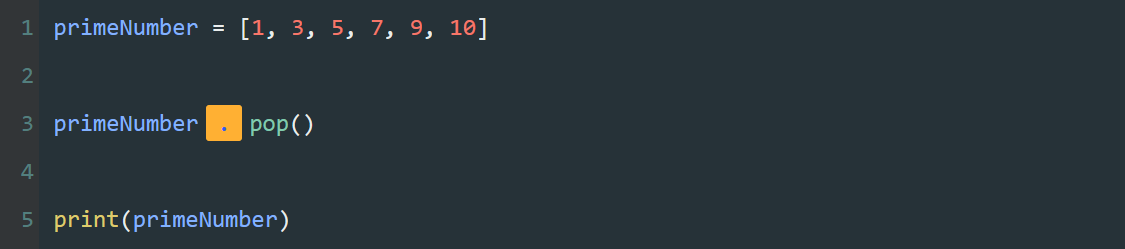
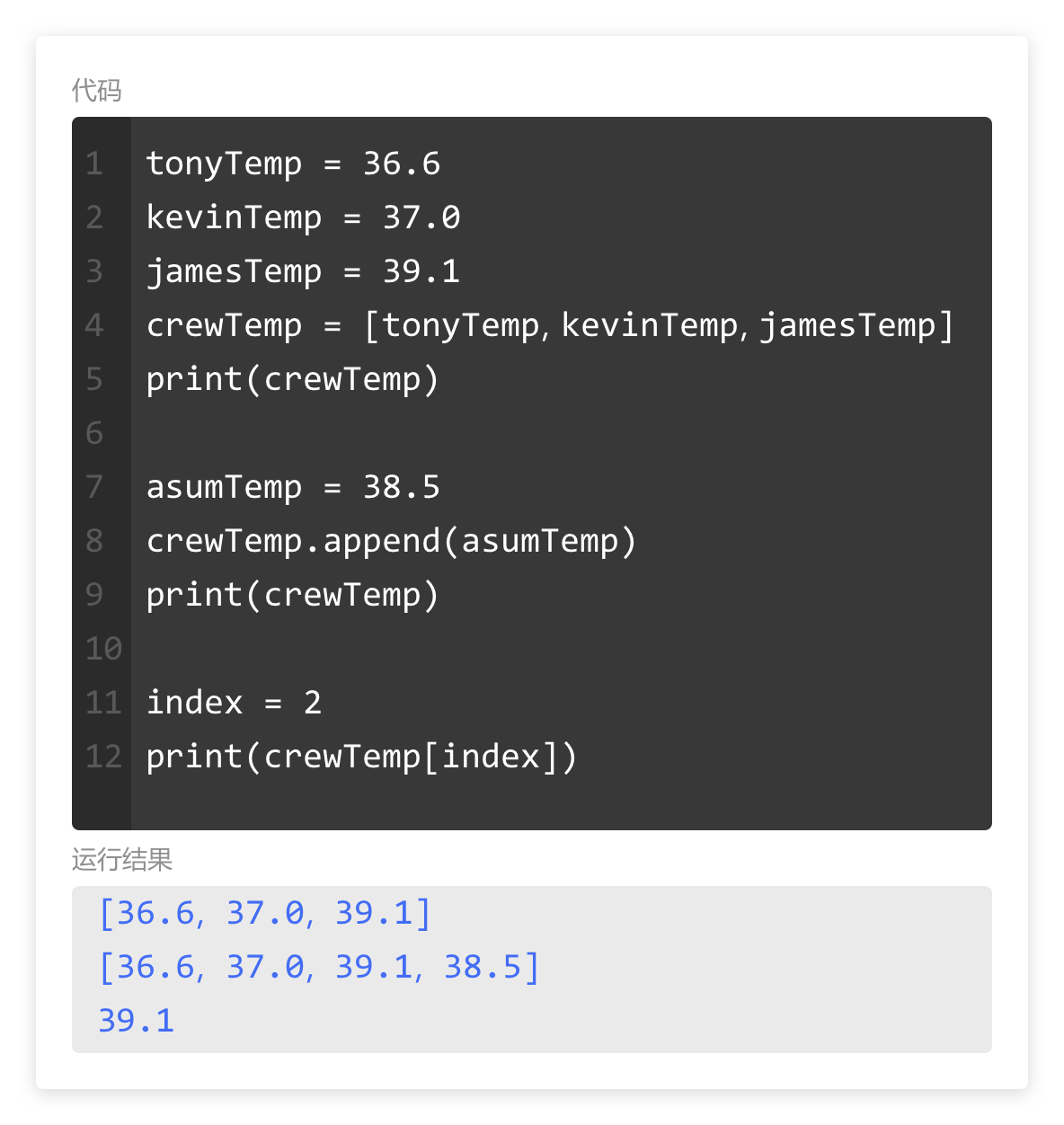
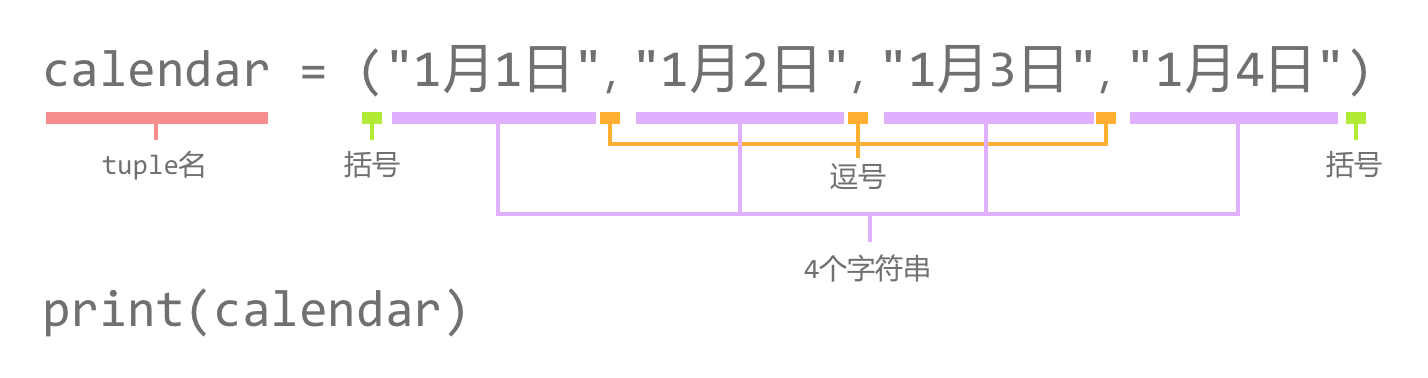
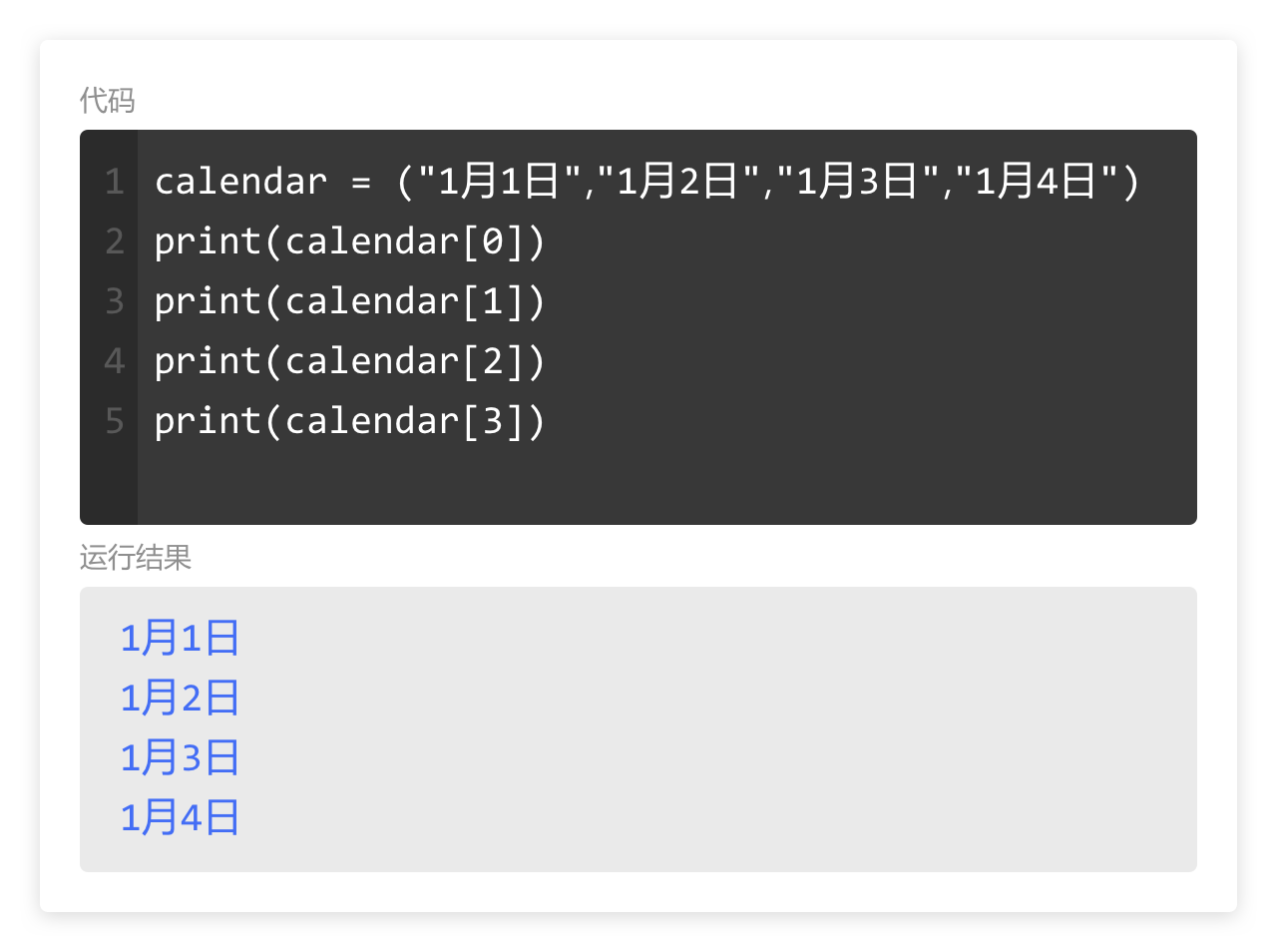
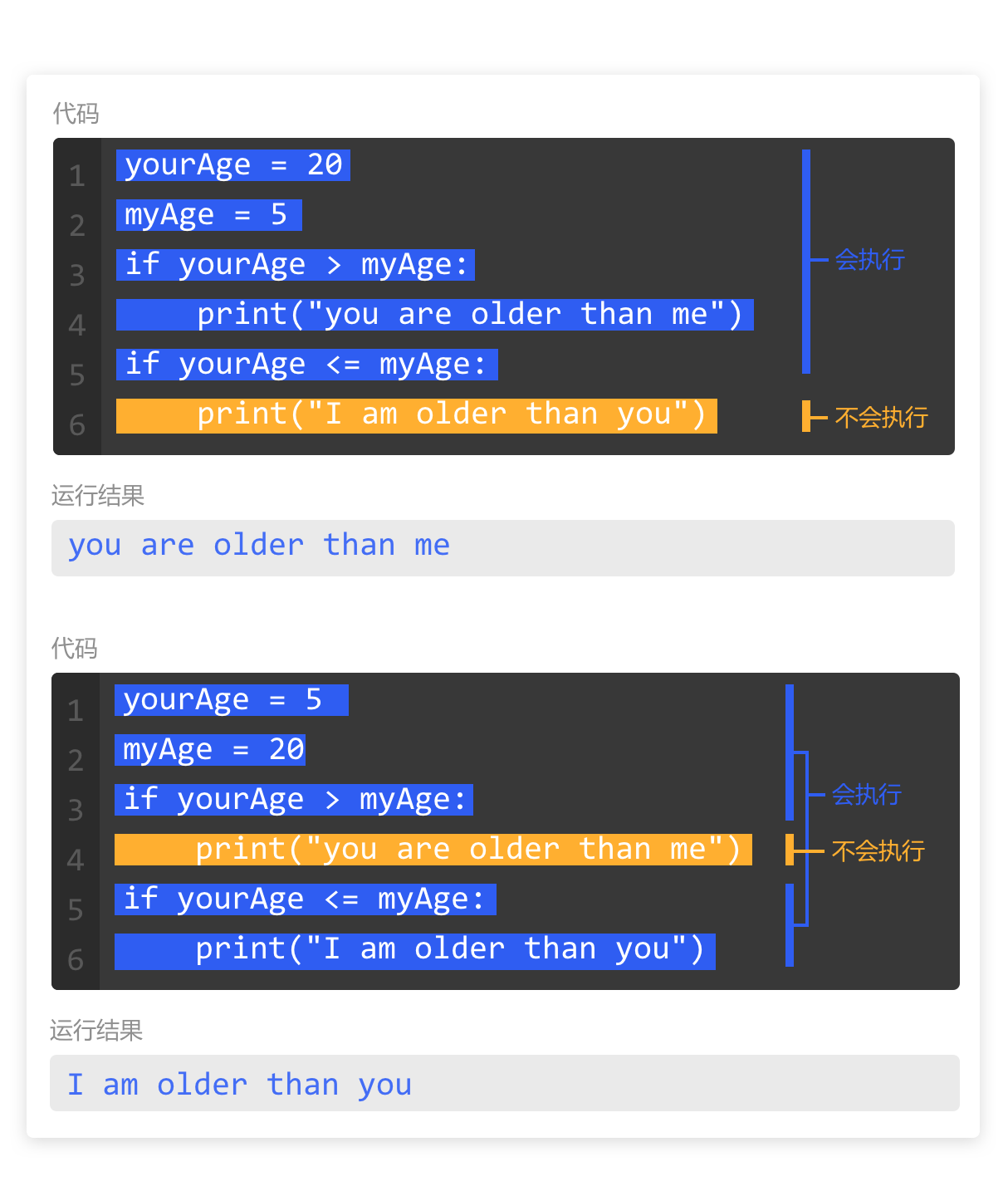
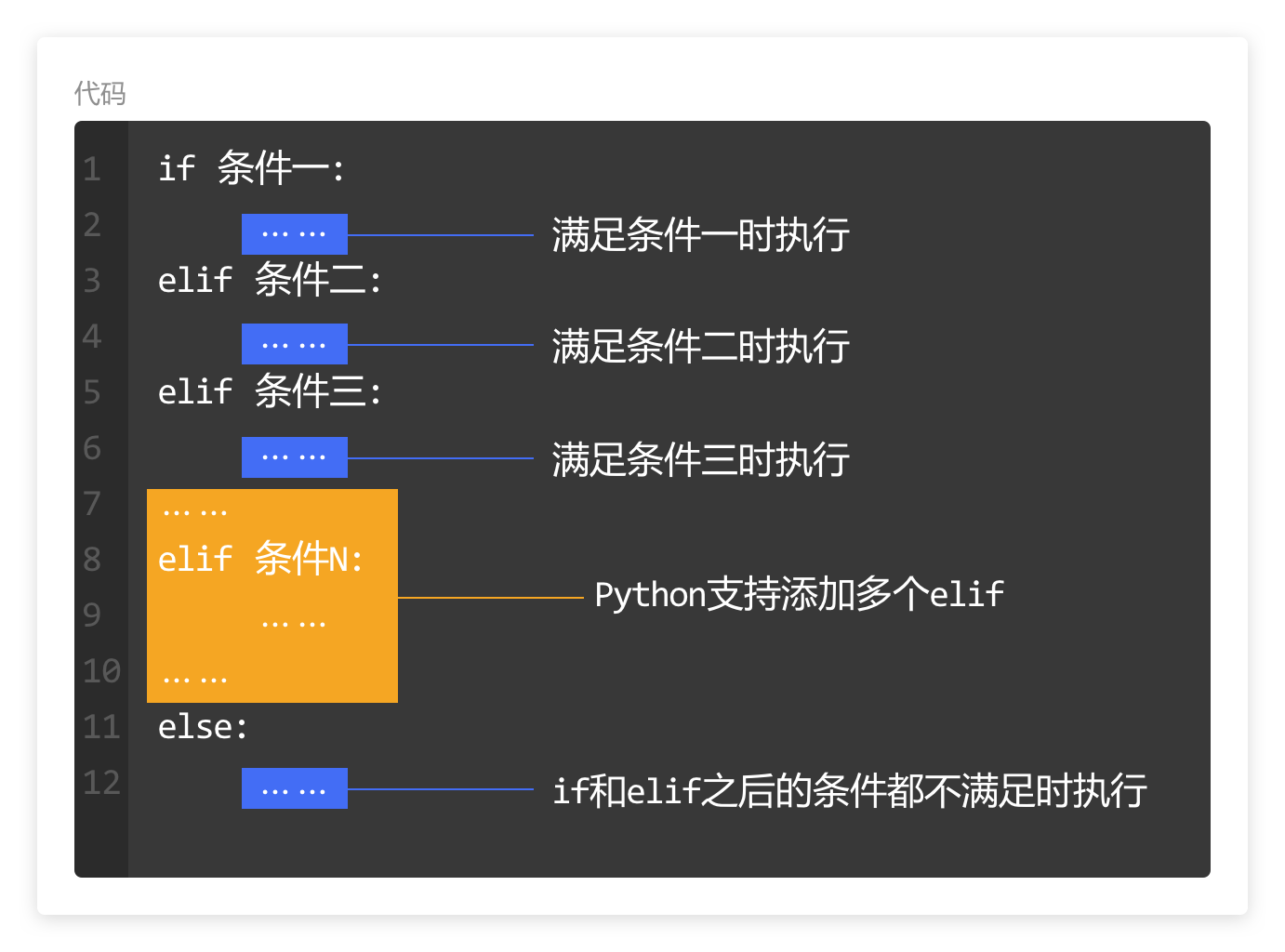
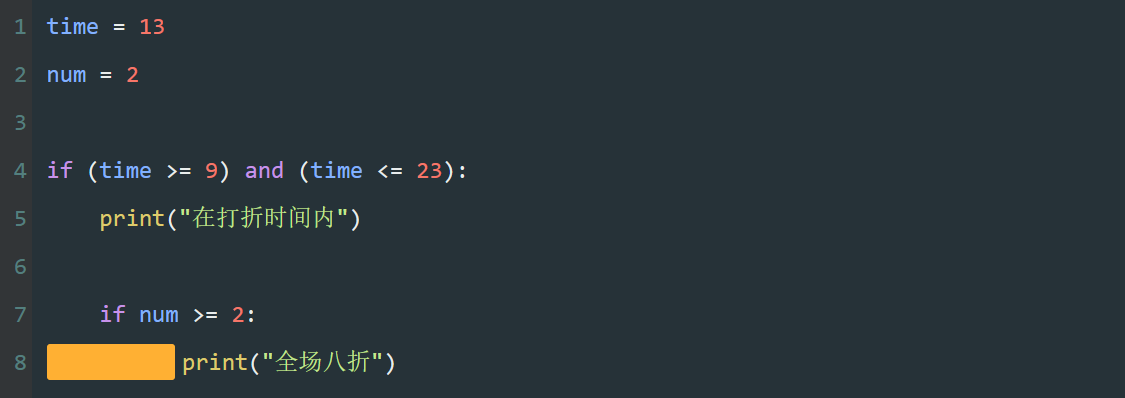
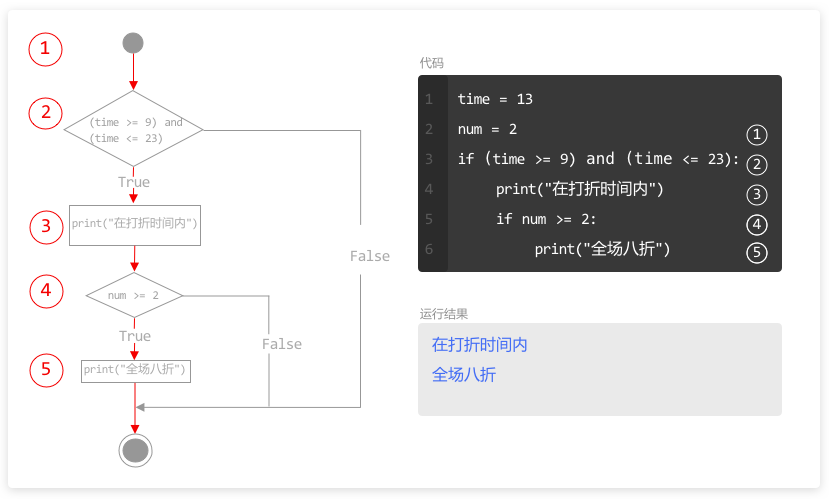
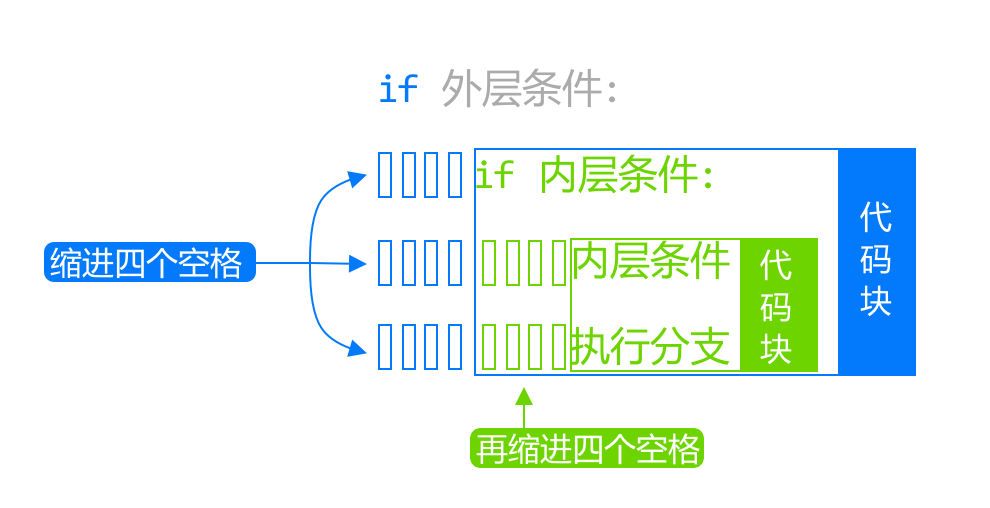
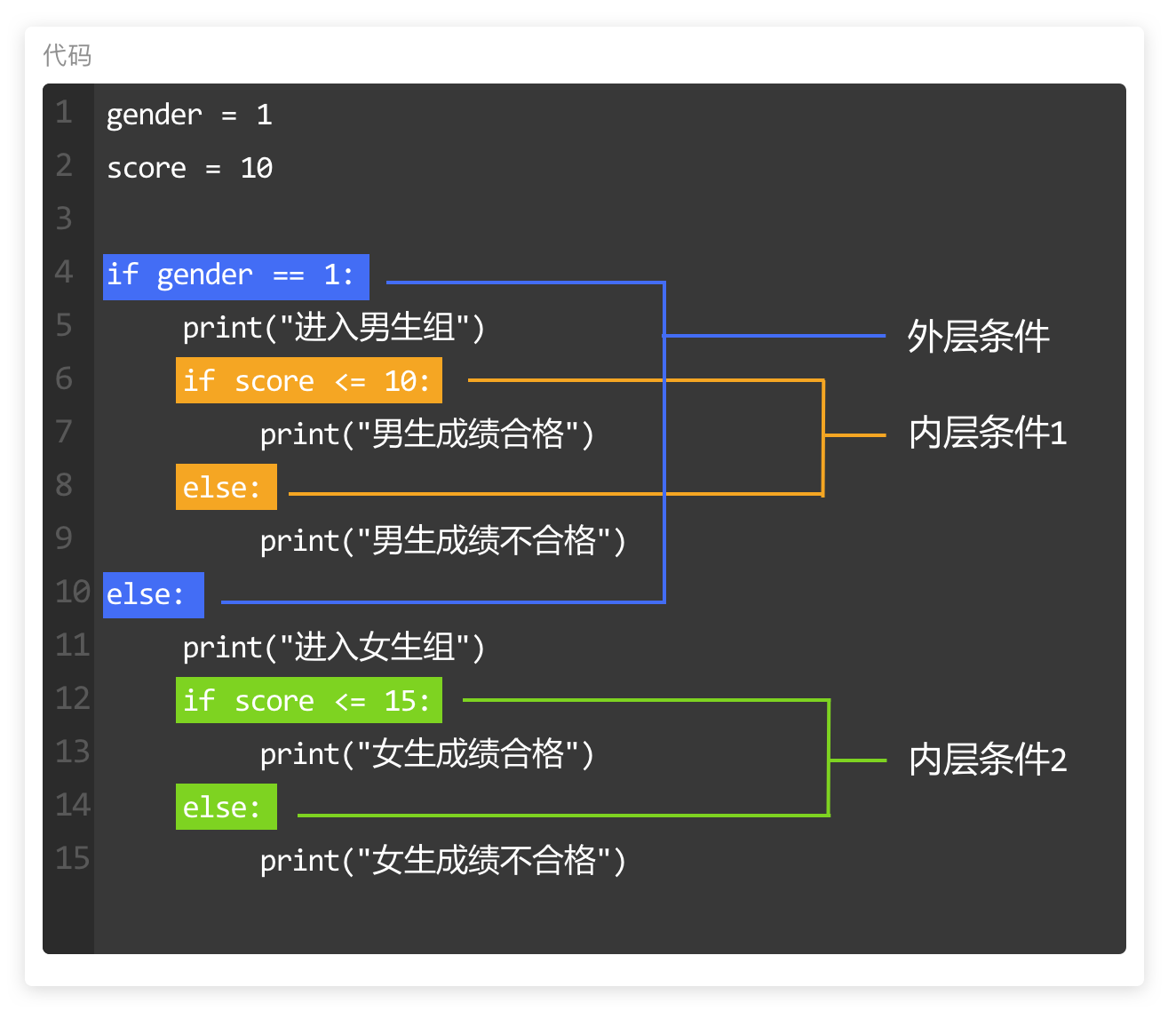
本系列文章的定义只是作为课程学习后的摘抄记录的笔记,非教程。
编程中的文本
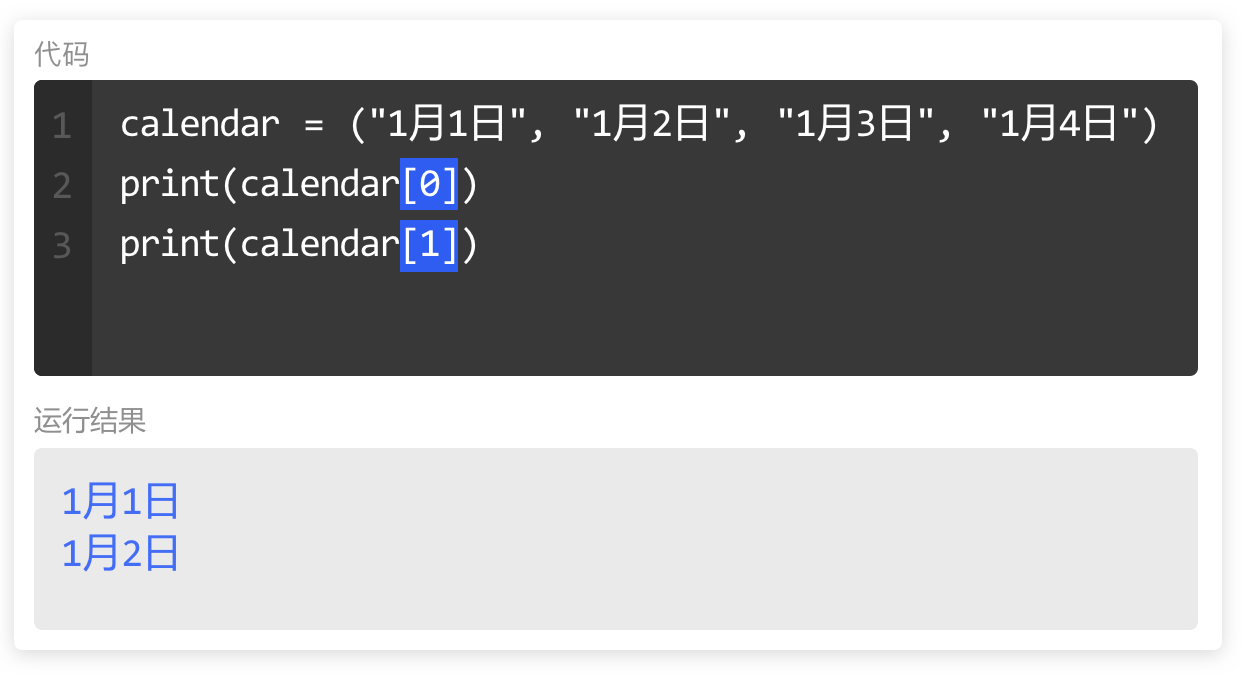
print()
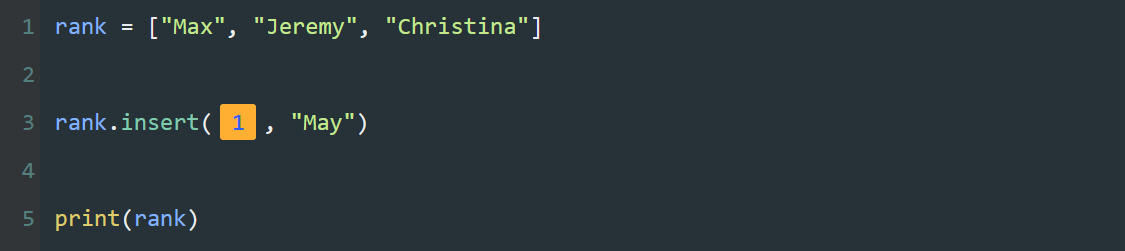
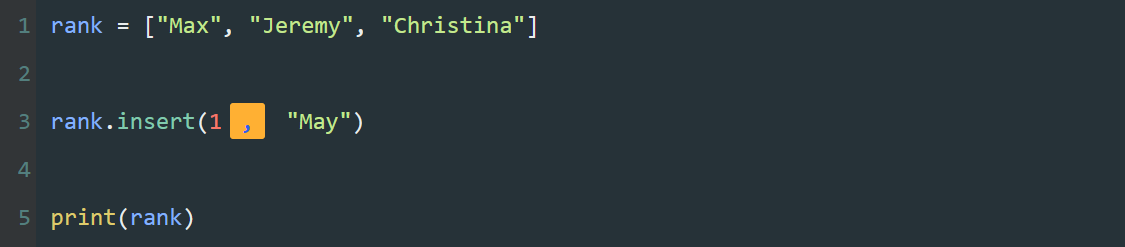
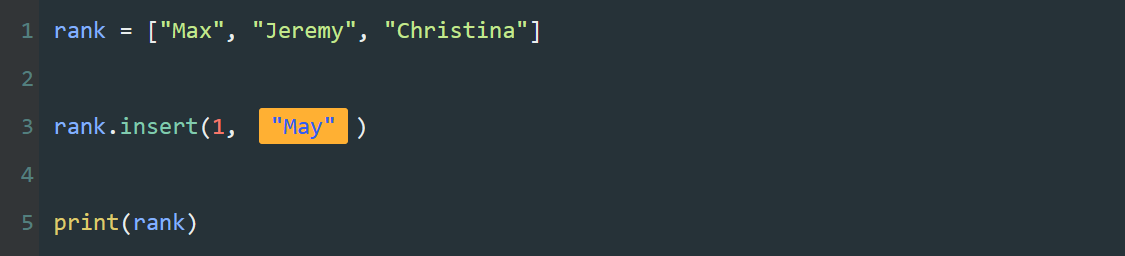
print()是Python里的输出函数,可用于输出内容。
print(101010)
print(1024)
格式
在这里,还需要注意 Python 的代码规范:
1. 空行
是指在代码之间用空行分隔,表示一段新的代码的开始。在编写时不插入空行,Python运行也不会出错。
2. 顶格
同一级别的代码需要顶格开始写,不能有空格,不然程序会报错。

字符串
使用 print() 语句输出一串英文。
print("hello world!")
使用 print() 语句输出英文的时候,需要加上引号。
这是因为 "hello world!" 这种用双引号括起来的结构,在 Python 中是一种数据类型,它的正式名称叫做字符串。
表示文本的数据类型。所有用引号括起来的数据,数据可以是英文、中文、数字、表情包等等,都是字符串。
注:在 Python 中,使用单引号或是双引号都可以创建字符串。为了统一格式的情况下,使用一种即可。
print("(≧∇≦)ノ")
print("2021")
print("夜曲")
print("hello world!")
print('hello world!')
代码小结
当要输出字符串就需要这几个部分

注释

Python中使用#(井号)用于注释。
#位于注释行的开头,在 # 后空一格,与文本分开,这样内容不会堆积,看起来整洁和美观,然后接着是注释内容。
也可以在一条语句的末端进行注释。
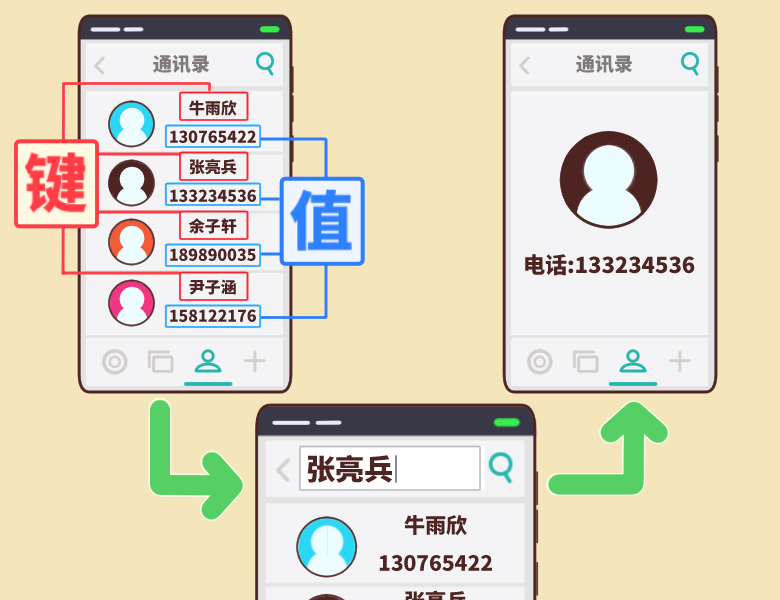
变量与赋值
变量
变量是编程语言中能存储数据的抽象概念,它可以存储各种数据。
变量名只能由字母、数字、下划线组成。
需要注意的是:
1. 不能以数字开头;
2. 不能包含空格;
3. 大小写敏感,变量A和变量a是不同的。

常量
常量是指在程序运行时不能被修改的数据。
比如整数 175,小数 52.5,字符串 "Tony" 都是常量,它们是不能被修改的。
赋值
如同把饮料倒入水杯一样,在 Python 中, 把一个常量放入变量的过程就叫做赋值。
赋值需要用到等号“=”,所以等号“=”又叫做“赋值运算符”。
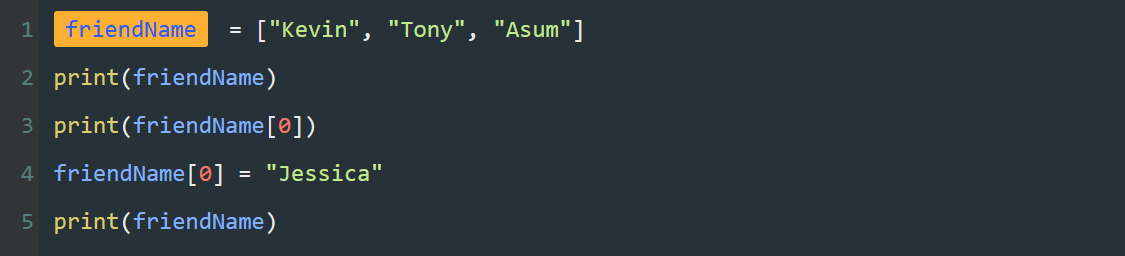
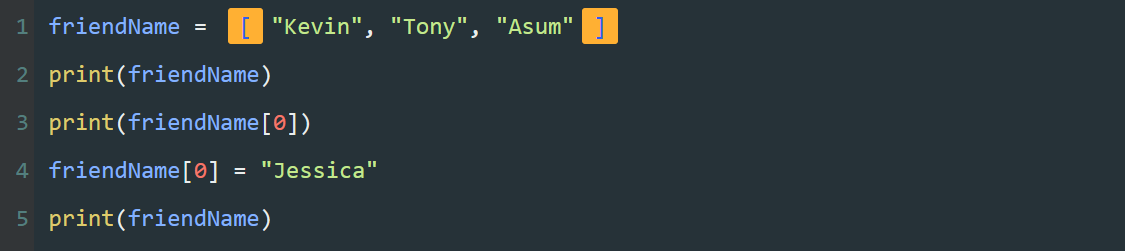
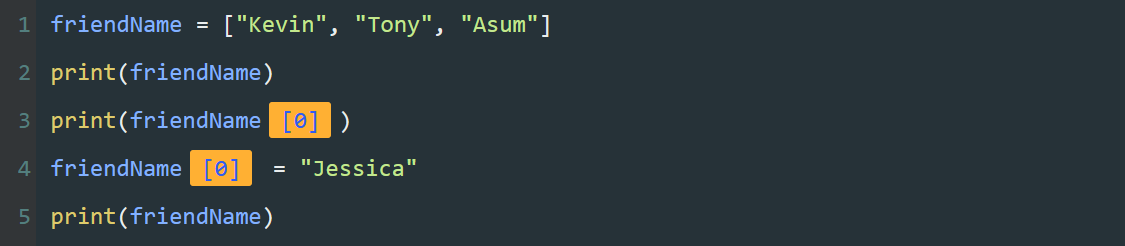
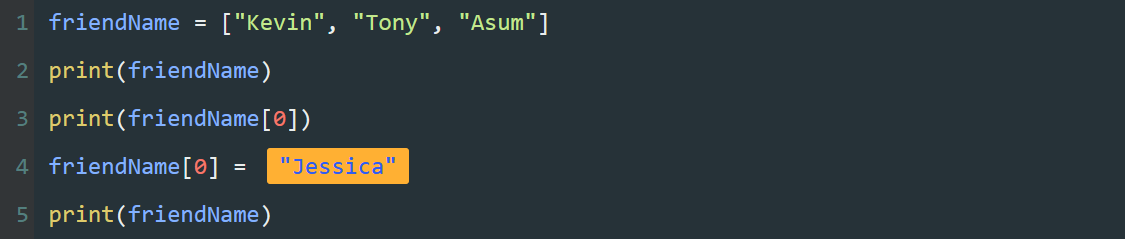
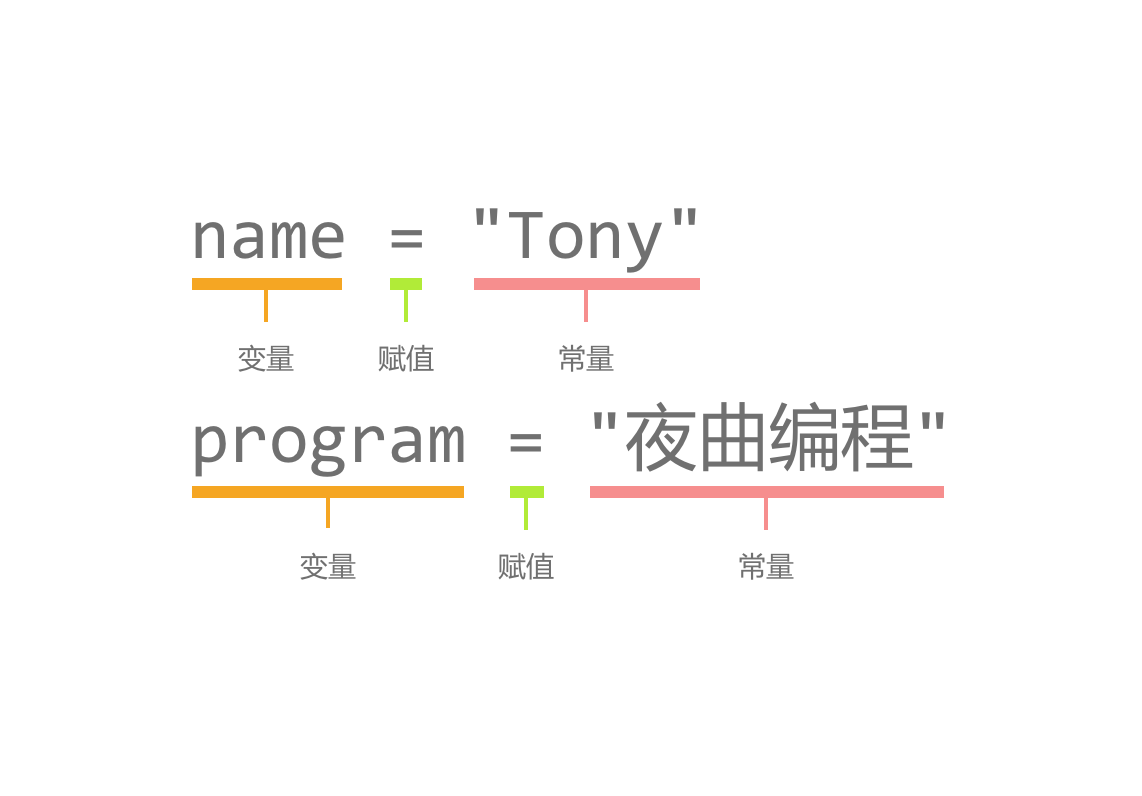
name = "Tony"
program = "夜曲编程"
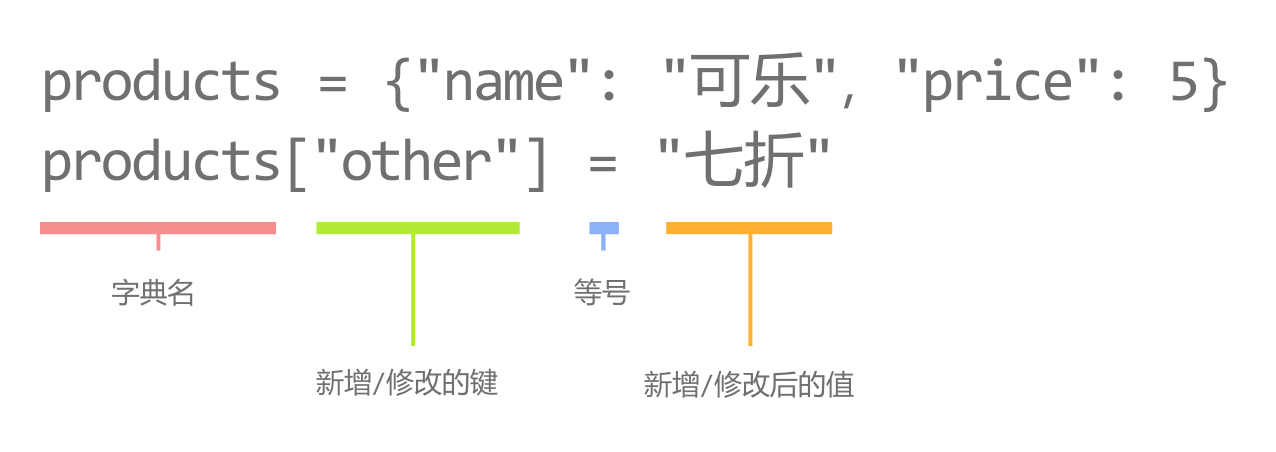
常量
图中的字符串 "Tony" , "夜曲编程" 都是常量,可以将它们分别赋值给不同的变量。

赋值
赋值符号“=”代表把一个数据装入变量的过程。
比如,我们把 "Tony" 装入 name ,这个过程就叫赋值。

变量
图中的 name 、 program 都是变量,一个类似容器的东西,可以用来存储不同的数据。

代码小结
要给一个变量赋值就需要这三个部分
name = "Downey"
name = "Tony"
print(name)
如果给一个变量多次赋值新的常量,在两次赋值之后,输出了最后一次赋值的值 Tony。
变量作为一个存储数据的“地方”,其中的东西是可以改变的,但是它每次只能存放一个东西,当我们放入别的东西时,之前的东西就会被丢弃,只留下最后一次放入的东西。

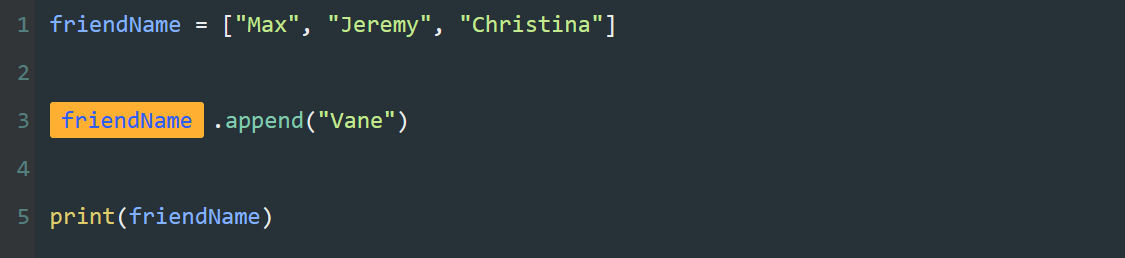
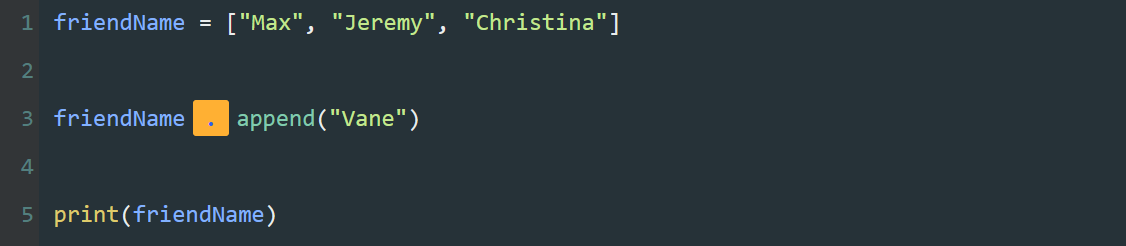
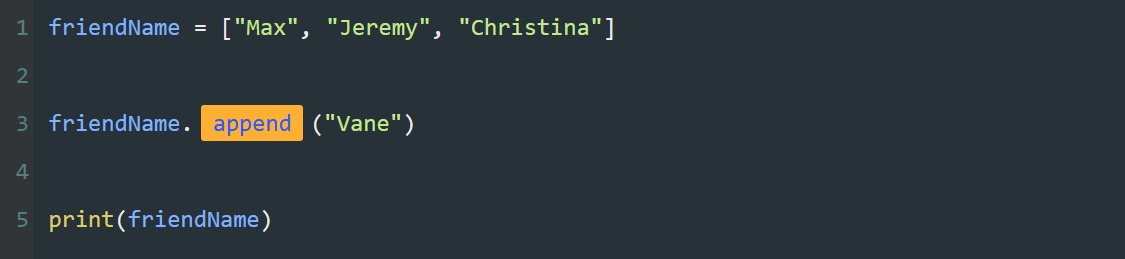
此外,在 Python 中,除了用常量给变量进行赋值,还可以用一个变量给另一个变量赋值。
ABC = 1024
abc = ABC
print(abc)
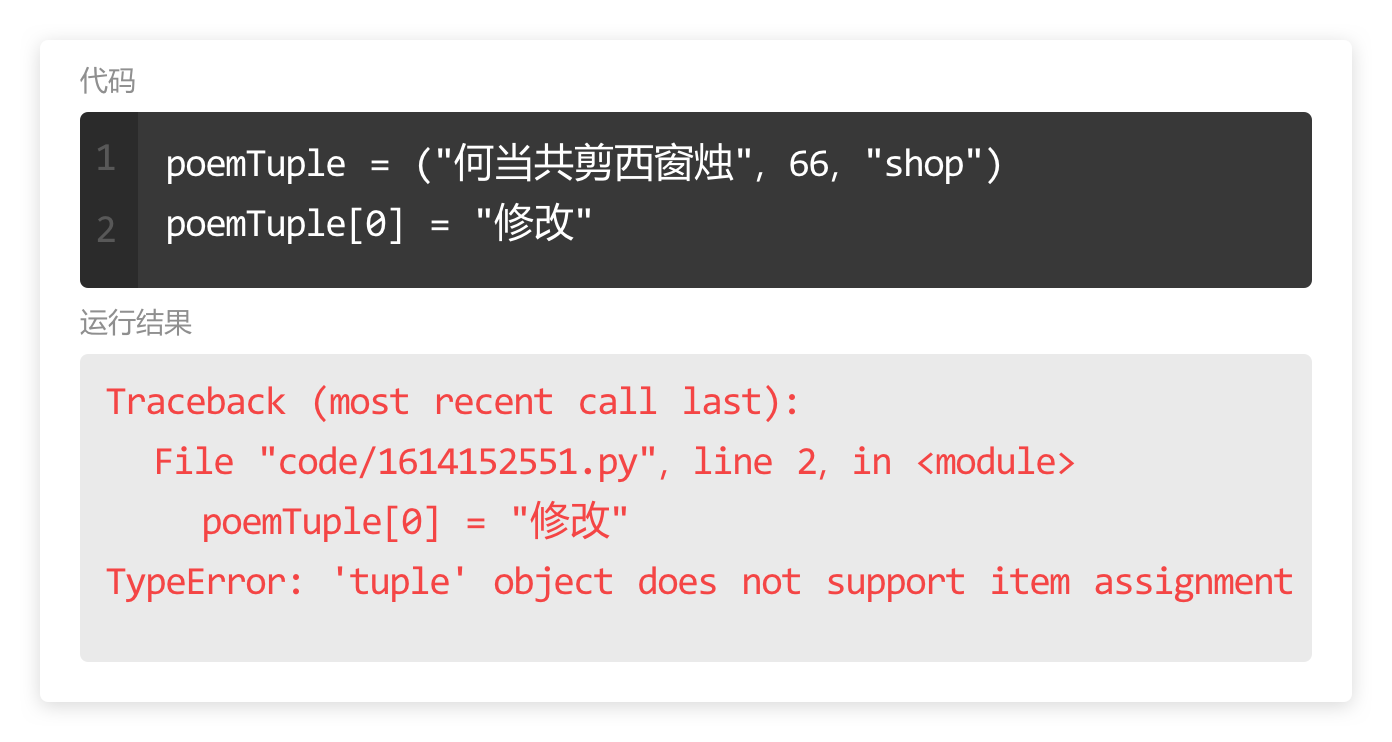
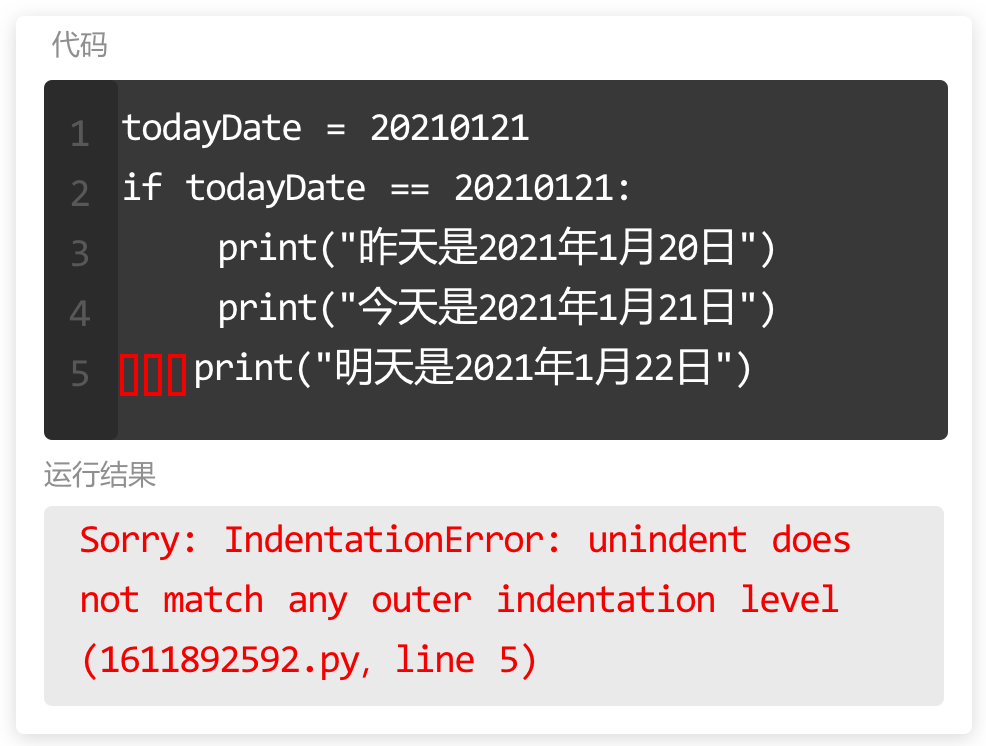
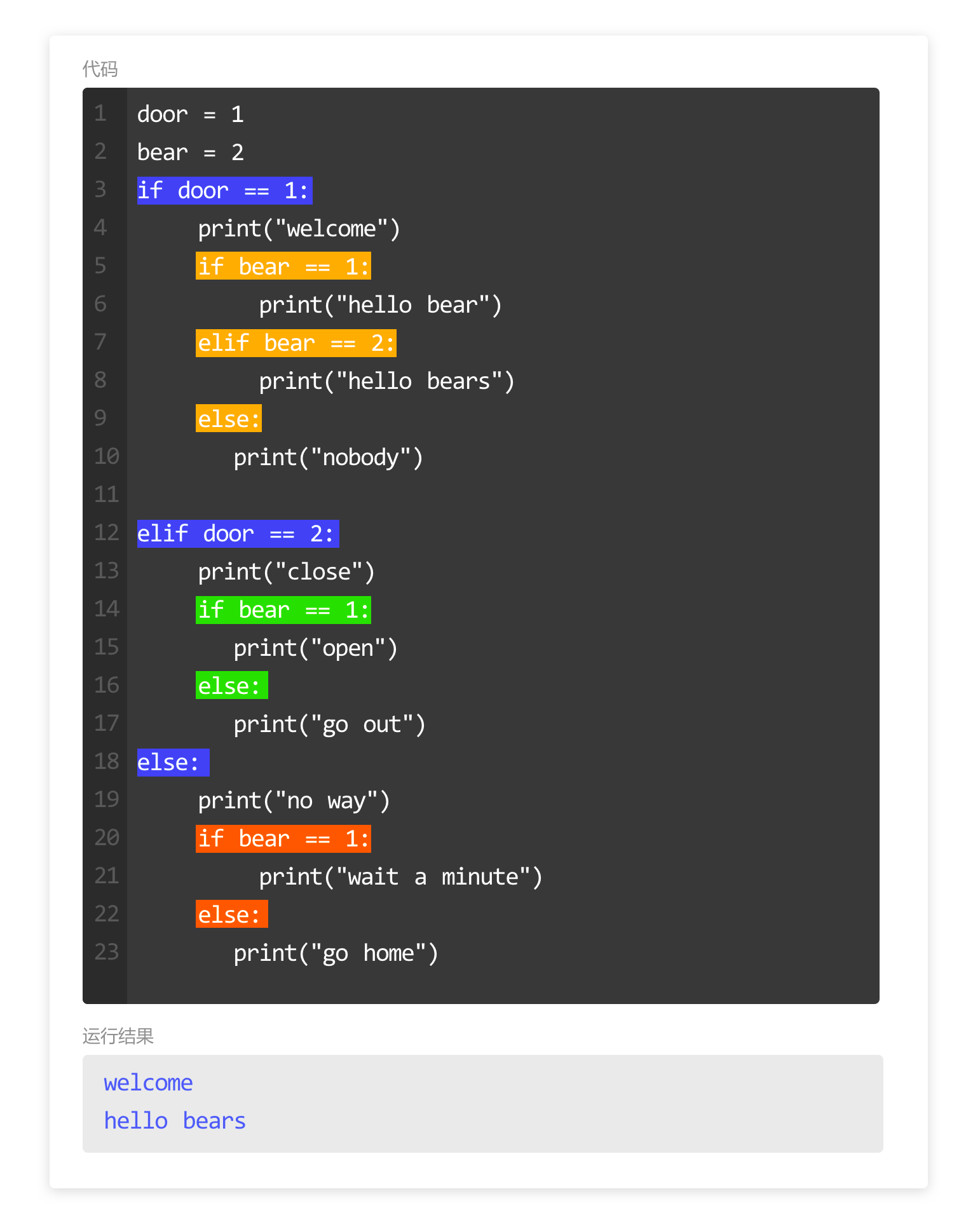
学习在使用变量时,常见的代码报。
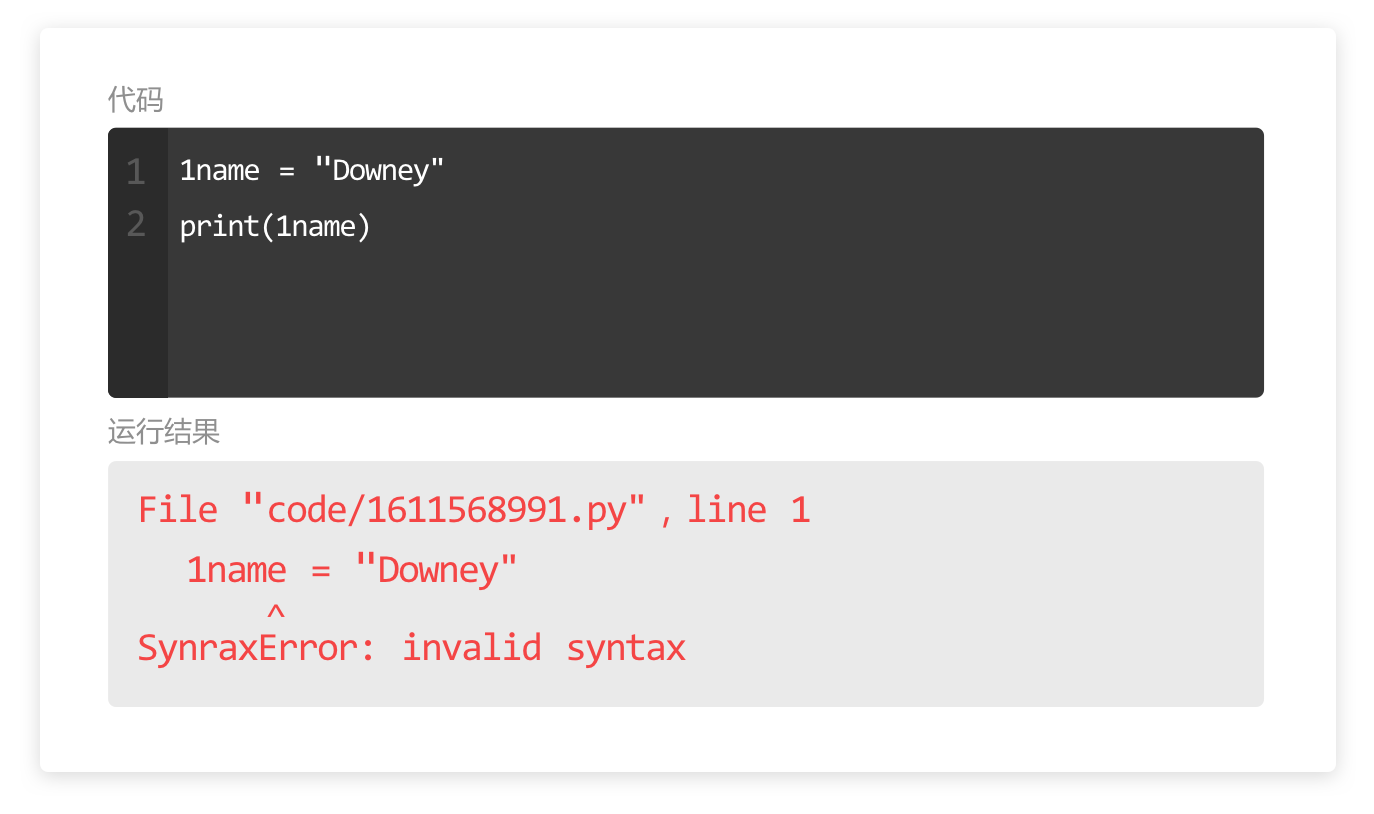
如图所示,这个报错提示说明:
1. 出错的行数是第1行;
2. 出错的具体代码是 1name = "Downey",
1name 的下方有一个小箭头表示 bug 在这里;
3. 错误类型是 SyntaxError,表示语法错误,
invalid syntax 是无效语法,说明变量定义出错了,仔细检查不难发现,变量命名错误,不能以数字开头。

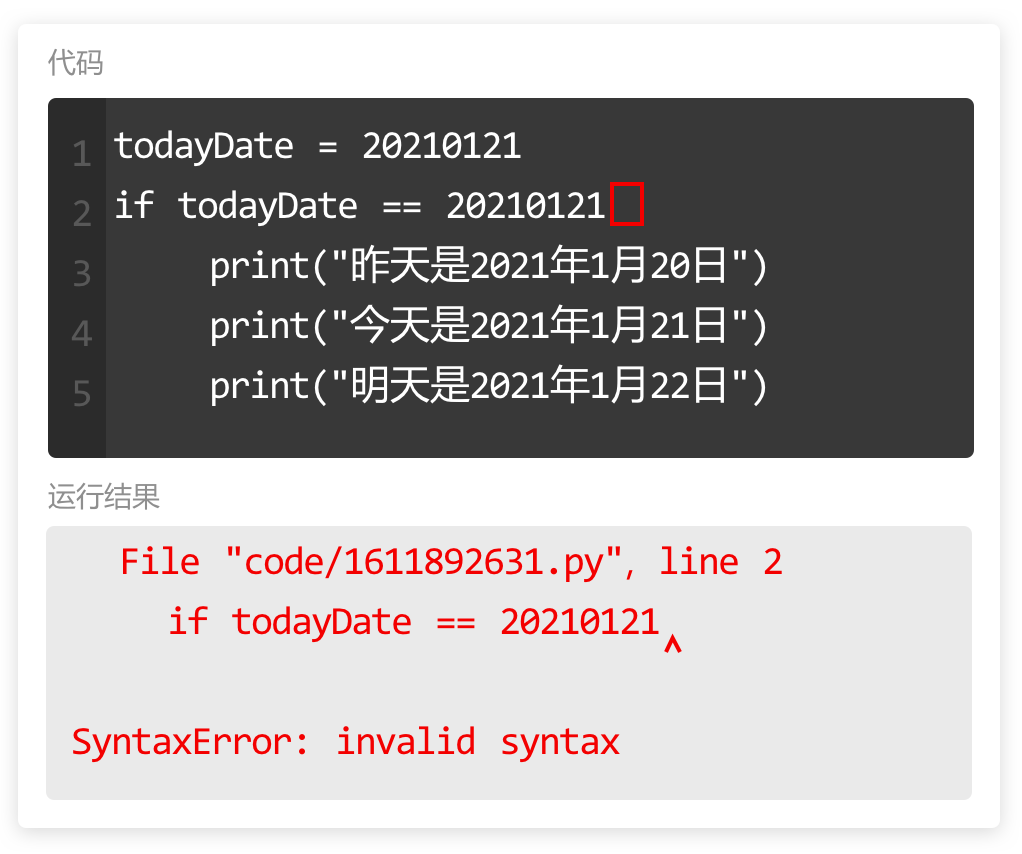
这个报错提示说明:
1. 出错的行数是第2行;
2. 出错的具体代码是 print(name111);
3. 错误类型是 NameError,表示名称错误,
“name 'name111' is not defined”是名称“name111”未定义,仔细检查不难发现,我们定义的变量是 name 而不是 name111。
格式化输出
格式化输出让我们可以对字符串里的内容进行灵活替换。
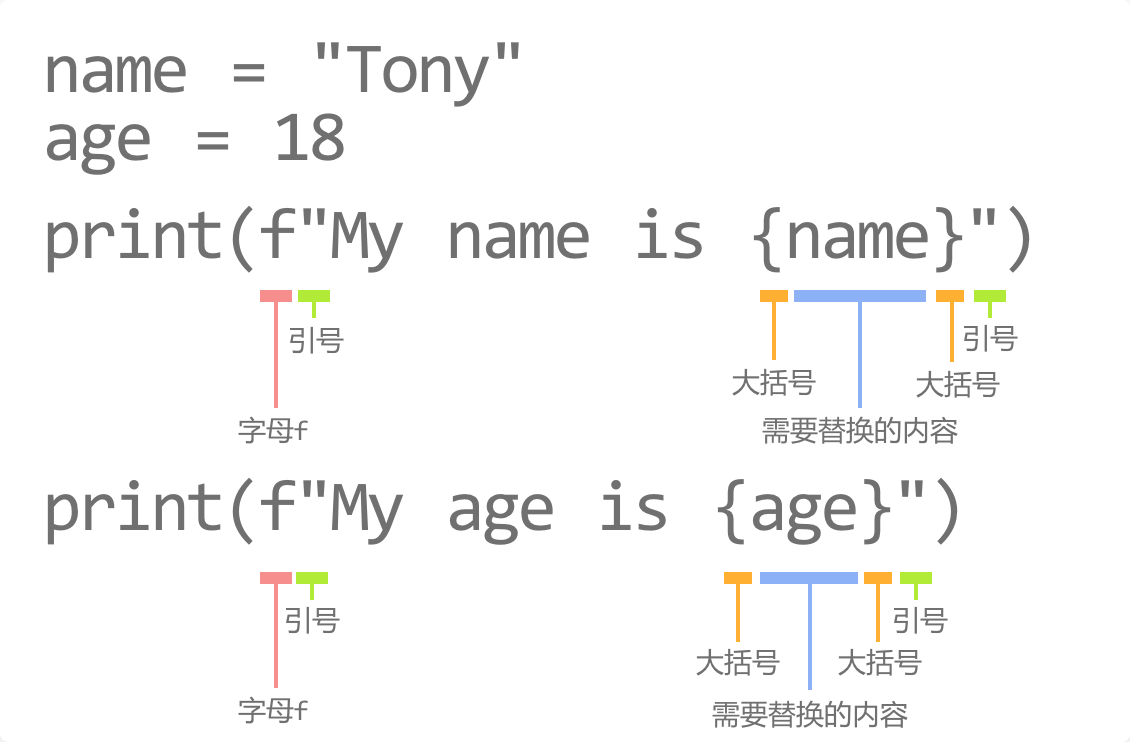
name = "Tony"
print(f"My name is {name}")
name = "Mike"
print(f"My name is {name}")
# output
# My name is Tony
# My name is Mike
f
字符串之前的小写字母 f 表示这个字符串需要进行格式化输出。
注意⚠️ ,不可以使用大写字母 F

双引号
通过使用双引号" ",我们分别定义了两个字符串"My name is {name}"。

大括号
大括号 { } 标记了字符串中需要被替换的内容。

需要替换的内容
大括号括起来的,是需要替换的内容。
在这个例子里,就是变量 name 被赋予的值。

代码小结
要对一个字符串进行格式化输出时,就可以使用这样的格式
转义字符
转义字符是一种特殊的字符,它们以反斜线 \ 开头,例如换行符 \n 。
当字母 n 与反斜线 \ 结合后,它们的含义和功能相比之前发生了转变,因此这样的字符被称为转义字符。
如图所示,除了 \n 之外,转义字符还有很多。

字符串 加 换行符 \n 的格式
print("第一行内容,\n第二行内容,\n第三行内容,\n第四行内容。")
# output
# 第一行内容,
# 第二行内容,
# 第三行内容,
# 第四行内容。
编程中的"数字"
Python中,字符串用来表示文本,用什么表示数字呢?
整型就是整数的数据类型,用来表示整数的。
整数在Python的世界中,和数学中的定义一样: 是正整数、负整数和零的统称,是没有小数点的数字。
整型
在Python中,整型是用来表示整数的数据类型, 是编程语言里用来呈现和存储整数的一种方式。
和字符串不同的是,整型直接通过数字来表示,无需添加引号。
如果用来表示负数,可以在数字前添加一个负号(-)。
同样的,使用print()也可以输出一个整型数据。
print(2022)
print(365)
print(-100)
浮点型
在Python中,浮点型是用来表示浮点数的数据类型,是编程语言里用来呈现和存储小数的一种方式。
它通过数字和小数点来表示,无需添加引号。
如果表示负数,可以在数字前添加一个负号(-)。
print(10.24)
print(7.01)
print(-3.9)
四则运算
整型和浮点型,都是表示数字的数据类型。
在Python中,表示数字的数据类型,可以进行加、减、乘、除的四则运算。
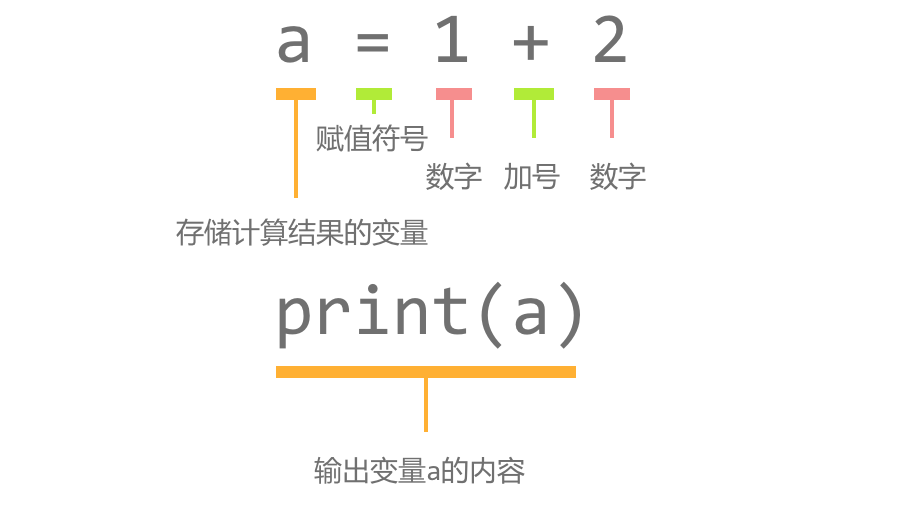
下面的代码用来计算两个数字之和,并且输出计算的结果。
a = 1 + 2
print(a)
完成一次四则运算就需要图中几个部分
乘法和除法在Python中的运算方式与数学中的运算方式一样,但使用的运算符号有所差异。
在Python中,乘号是*,除号是/。
乘法和除法在Python中的使用方式。
a = 2
b = 4
print(a * b)
print(a / b)
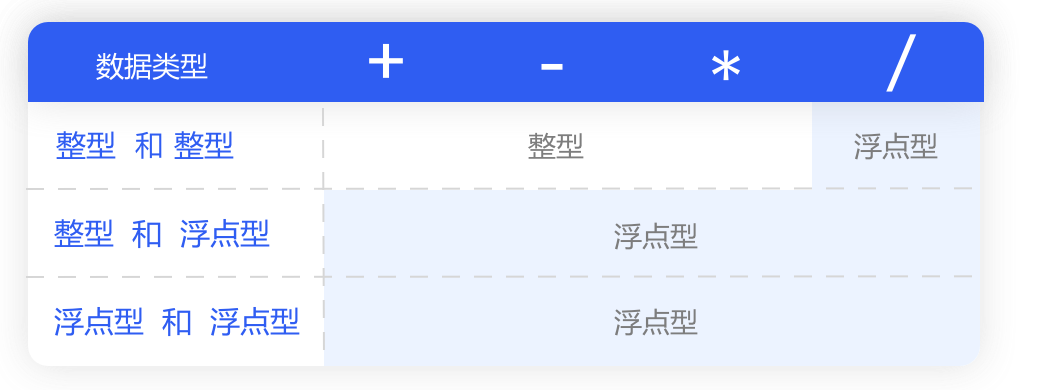
浮点型的运算方式和整型的运算方式基本一样,但运算结果的数据类型,有3种情况:
1. 整型之间加、减、乘法的计算结果是整型。
a = 2
b = 4
print(a * b) #8
2.整型之间除法的计算结果,都是浮点型。
就算刚好整除,也会得到一个浮点型数据。
a = 4
b = 2
print(a * b) #2.0
3. 浮点型的计算结果是浮点型,只要参与运算的双方有一个是浮点型,那么结果也是浮点型。
a = 4.0
b = 2
print(a * b) #8.0
print(a + b) #6.0
简单总结下,当整型和整型进行加、减、乘法运算时,运算结果是整型。
当整型和整型相除,或者有浮点型参与运算时,运算结果都是浮点型。
加法(+),减法(-),乘法(*),除法(/),在编程世界里有一个统一的称谓——运算符。
除了这四种常见的四则运算符之外,介绍另外两种运算符 —— 取整(//)和取模(%)。
取整和取模
当两个数无法整除的时候,我们会得到一个余数,例如:
7÷3=2......1,2被称作商,1被称作余数。
print(7//3)
print(7%3)
取整运算用于求取两个数相除之后的商。取整运算的符号是//。
取模运算用于求取两个数相除之后的余数。取模运算的符号是百分号 %。
代码小结
当我们取整取模时,就需要使用这样的格式

加上之前学习的赋值运算符(=),一共学习了7个运算符。
它们是:
赋值 =
加法 +
减法 -
乘法 *
除法 /
取整 //
取模 %
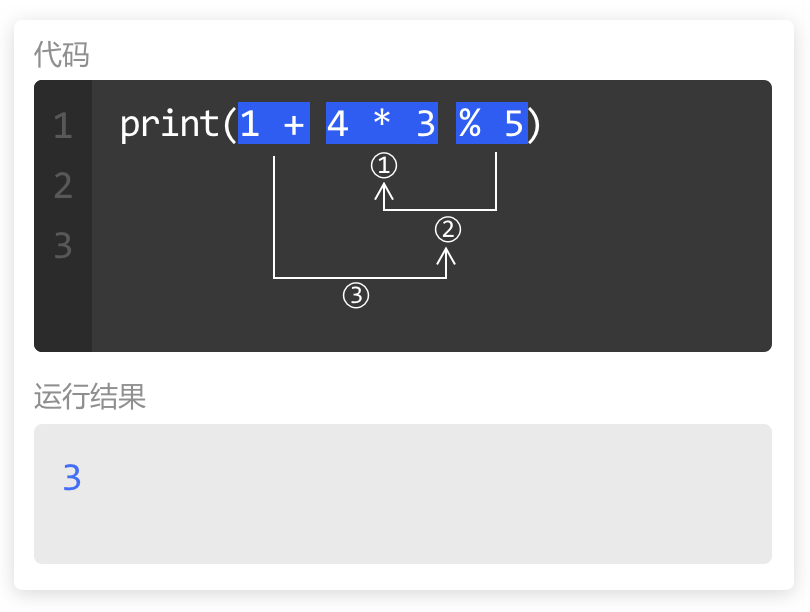
四则运算,遵循“先乘除,后加减”的运算顺序。
倘若运算中,包含了取整取模,就要遵循“先乘除取整取模,后加减”的运算顺序。
也就是,取整取模和乘除是同一等级,都会优先参与运算。
在Python中,整型数据可以和浮点型数据进行运算。
而一般情况,字符串是不可以和整型以及浮点数数据进行运算的。如图所示,若进行运算,计算机会报错“TypeError”。
仅有两种情况下,字符串可以进行运算:

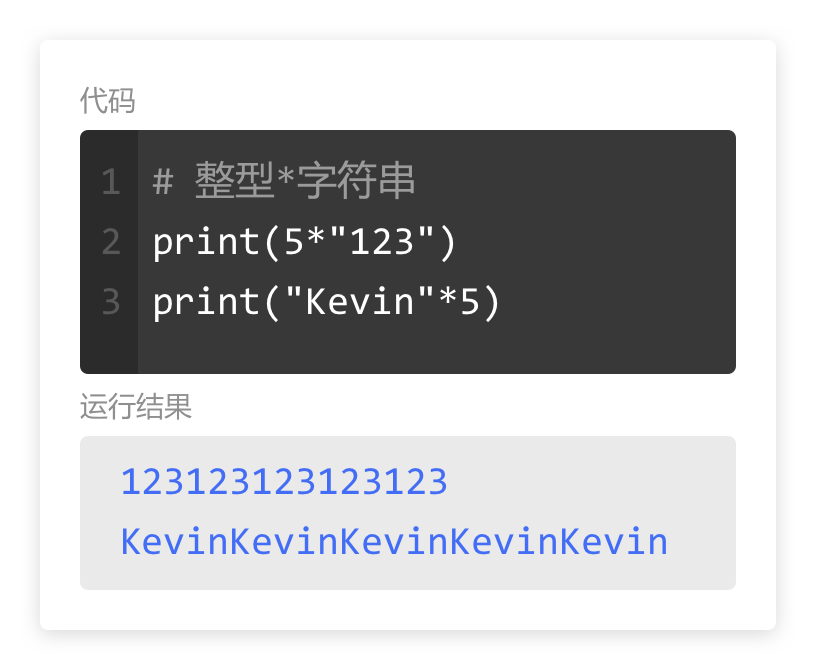
1. 整型和字符串相乘
整型*字符串,输出的结果,是将字符串重复几次拼接在一起。
如图,5*"123",输出是将"123"重复5次拼接在一起;"Kevin"*5,输出是将"Kevin"重复5次拼接在一起。
2.字符串和字符串相加
字符串+字符串,输出的结果,是这几个字符串的拼接。
如图,"123"+"123",输出是将"123"和"123"拼接在一起;"Kevin"+"123",输出是将"Kevin"+"123"拼接在一起。

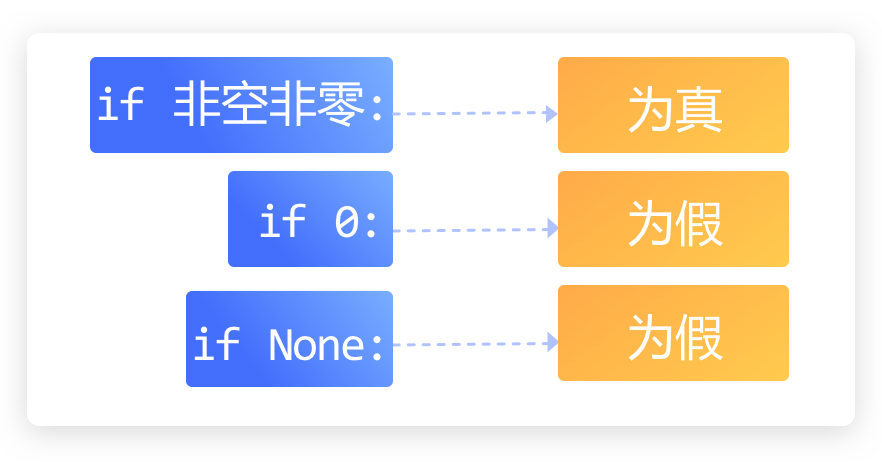
编程中的"真"与"假"
在编程中,这种“真”、“假”状态我们用布尔数来表示,“真”是True,“假”是False。
布尔数
布尔数是一种数据类型,它只有“真”(True)和“假”(False)两种值。
True 和 False 不加引号。
在Python中,可以通过直接赋值的方式,得到布尔数。
True 和 False 属于常量,赋值给变量。
Read = True
Adult = False
print(Read)
print(Adult)
另一种方式,是通过比较运算得到。
如下,3赋值给a,1赋值给b,进行大小的比较。
a > b,是“真”的,输出True;
a < b,是“假”的,输出False。
类似这样进行比较的行为,就是比较运算。
a = 3
b = 1
print(a > b)
print(a < b)
代码小结
进行比较运算的时候,就需要这样的格式

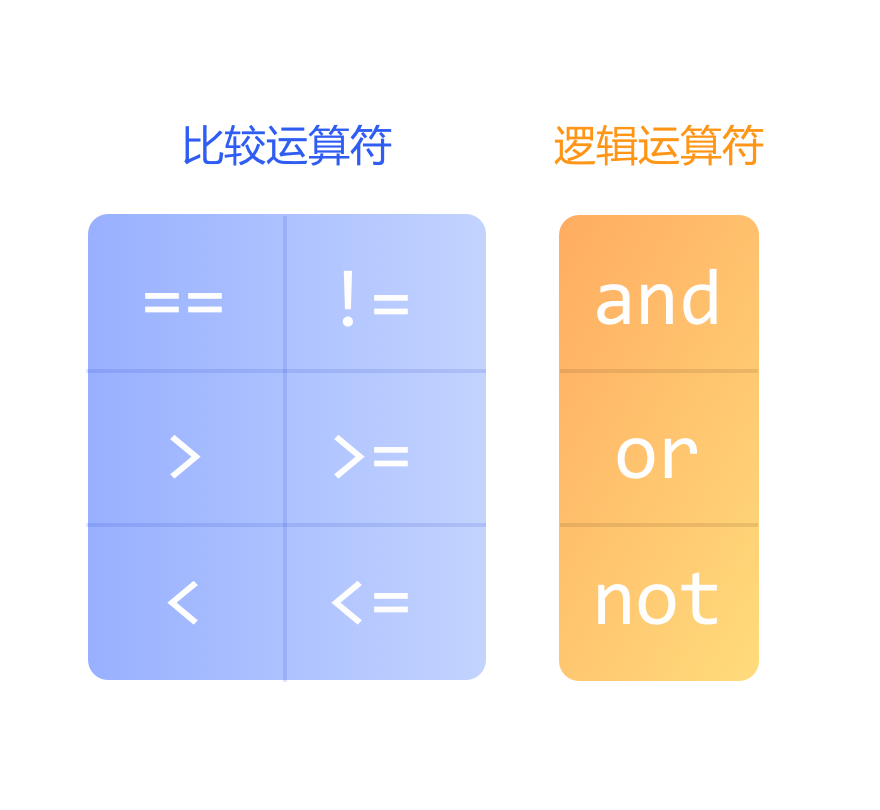
类似">","<"这样,对二者进行比较的,我们称为比较运算符。
除了">","<"这两个比较运算符以外,还有:
== 等于符号,注意是两个等号,要和=赋值区分开 ;
>= 大于等于符号;
<= 小于等于符号;
!= 不等于符号;

比较运算,可以根据单个条件,输出True或False的结果。
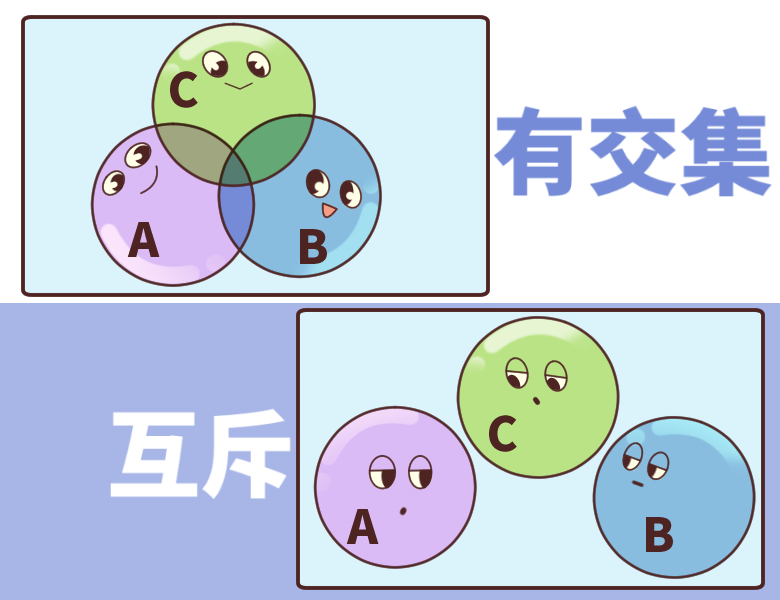
当对一个事物的判断涉及到多个条件的时候,就需要使用逻辑运算把多个条件连接起来。
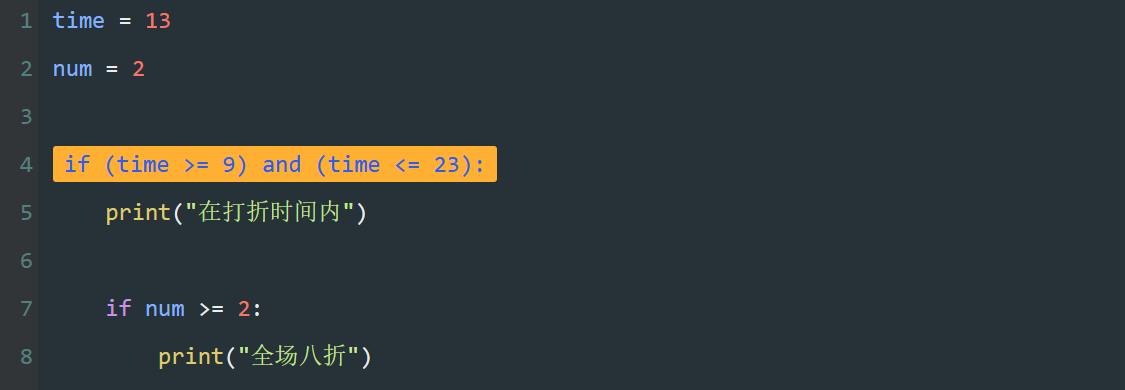
比如,我国男飞行员的身高要求是169 - 185厘米,换成逻辑表达就是“飞行员的身高必须要>=169厘米,并且,<=185厘米。
这里的“并且”就是一个逻辑运算。
逻辑运算
逻辑运算,是针对多个“真”、“假”命题进行判断的运算。
“并且”、“或者”和“非”是常见的三种逻辑运算。
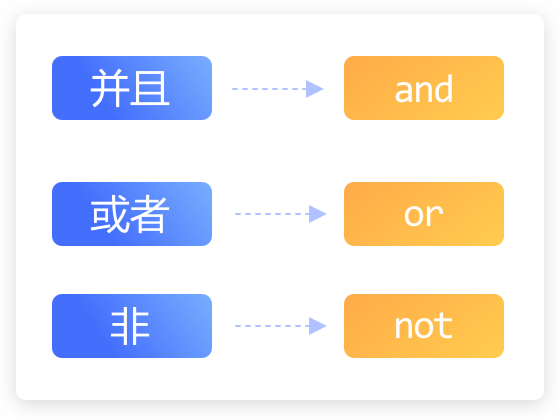
“并且”、“或者”和“非”这三种逻辑运算。在Python中,会用逻辑运算符来表达,包括:
and(并且)
or(或者)
not(非)。
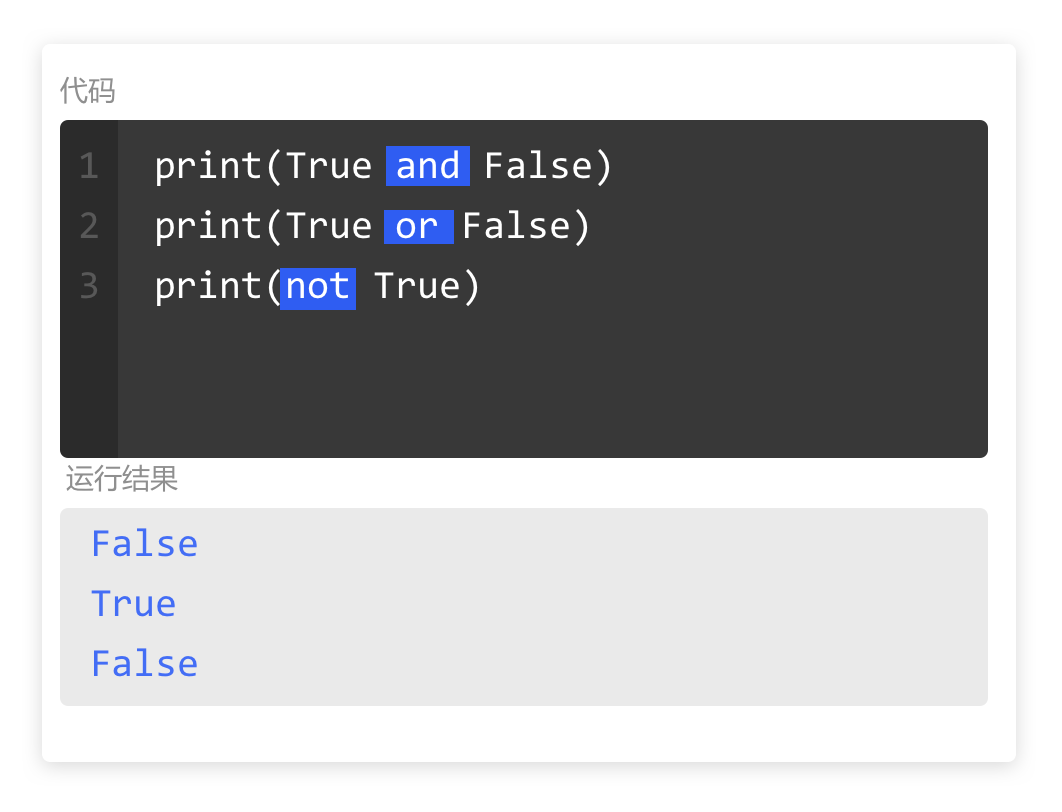
掌握了逻辑运算符的概念之后,分别学习这三个运算符的运算规则。
and运算符表示“并且”。
意思是仅当and左右两边的布尔数均为True时,运算结果才为True。
其它情况下,运算结果都为False。

or运算符表示“或者”。
意思是只要当or左右两边的布尔数有一个为True时,运算结果就为True。
也就是说,只有当or左右两边的布尔数均为False时,运算结果才为False。

not运算符表示“非”
与and和or不同,not运算符只会运算一个布尔数,表示对这个布尔数进行取反。
也就是说,not True 运行结果是False,not False运行结果是True。
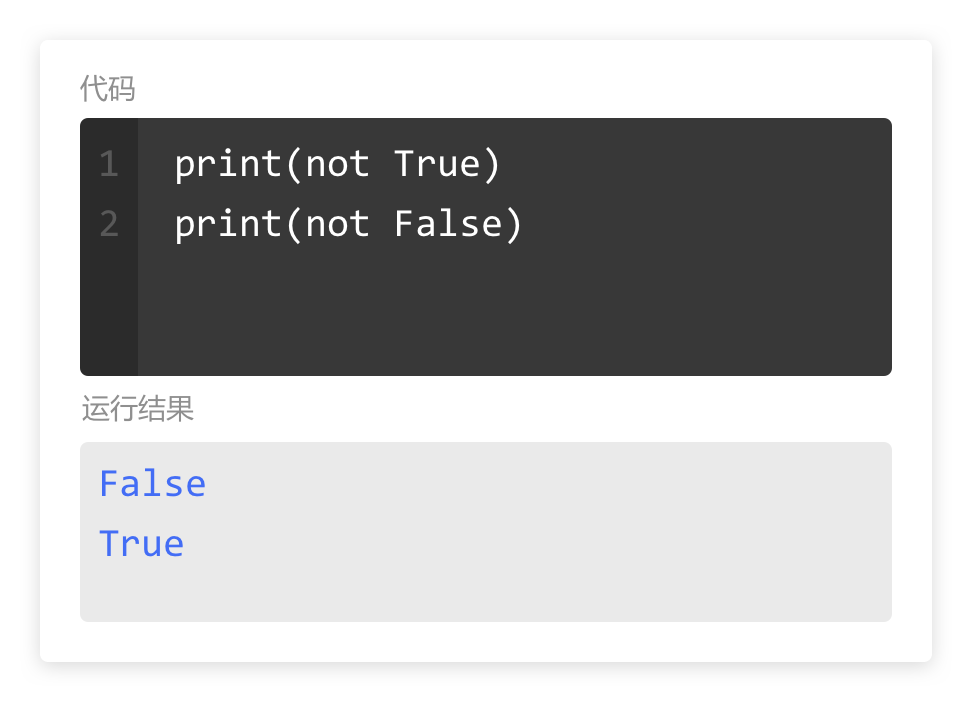
学习了逻辑运算的规则,学习一下具体的代码写法。
a = True
b = False
print(a and b)
print(a or b)
print(not a)
实例中,第1行代码给变量a赋值了布尔数True(真);
第2行代码给变量b赋值了布尔数False(假);
第3行代码输出了a和b进行and逻辑运算的结果。
第4行代码输出了a和b进行or逻辑运算的结果
第5行代码输出了a进行not逻辑运算的结果。
布尔数常量
True, 一个常量,“真”值。
False,一个常量,“假”值。

逻辑运算符
and,一种逻辑运算符号,表示“并且”。
or,一种逻辑运算符号,表示“或者”。
not,一种逻辑运算符号,表示“非”。

空格
and 和 or 运算符的两旁必须加空格,not 运算符后也必须加空格

代码小结
当完成一次逻辑运算,就需要这几个步骤

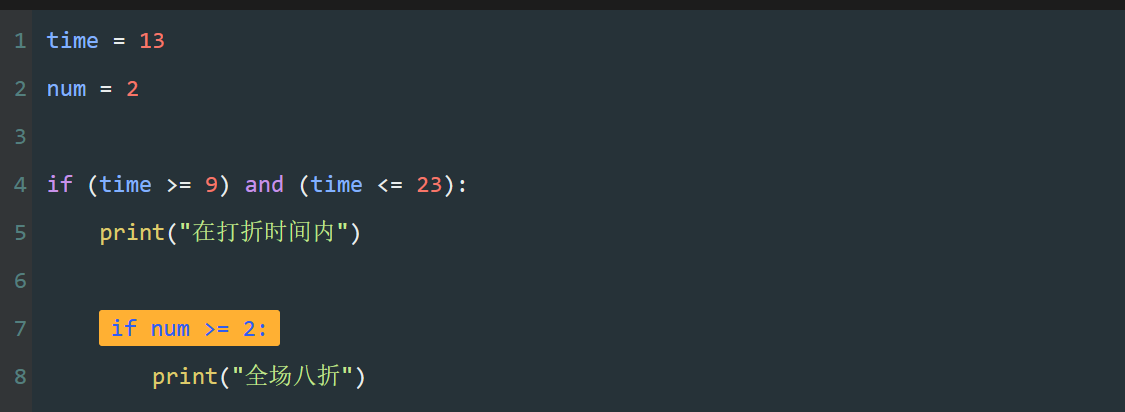
当涉及多个条件时,在Python中常会将比较运算和逻辑运算混合使用。
在此时,Python会优先执行比较运算,再按从左到右的顺序执行逻辑运算。
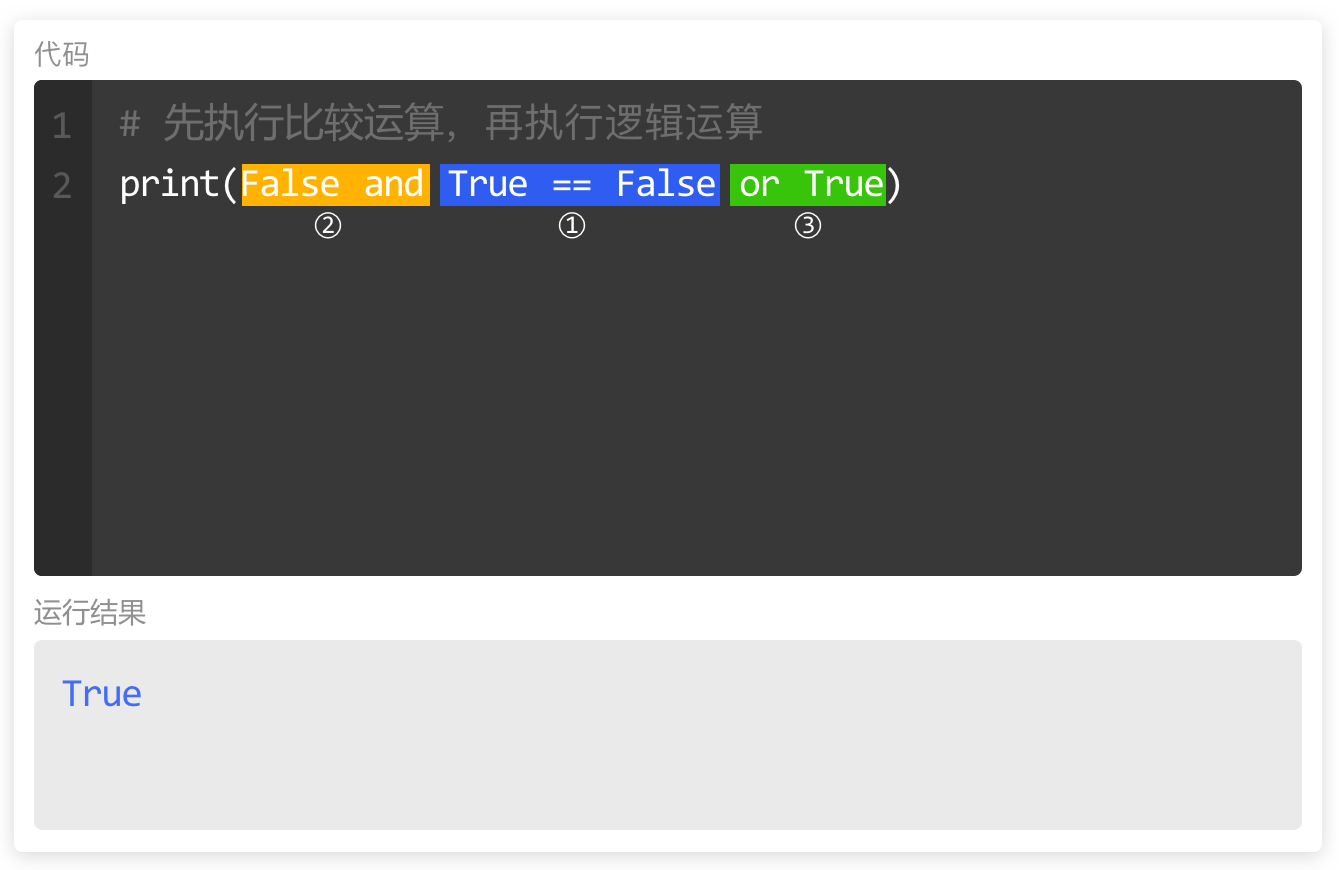
如果想控制代码执行的顺序,需要对希望优先执行的运算使用括号。
如图,使用括号后,运算顺序将完全不同,运算结果也会不相同。
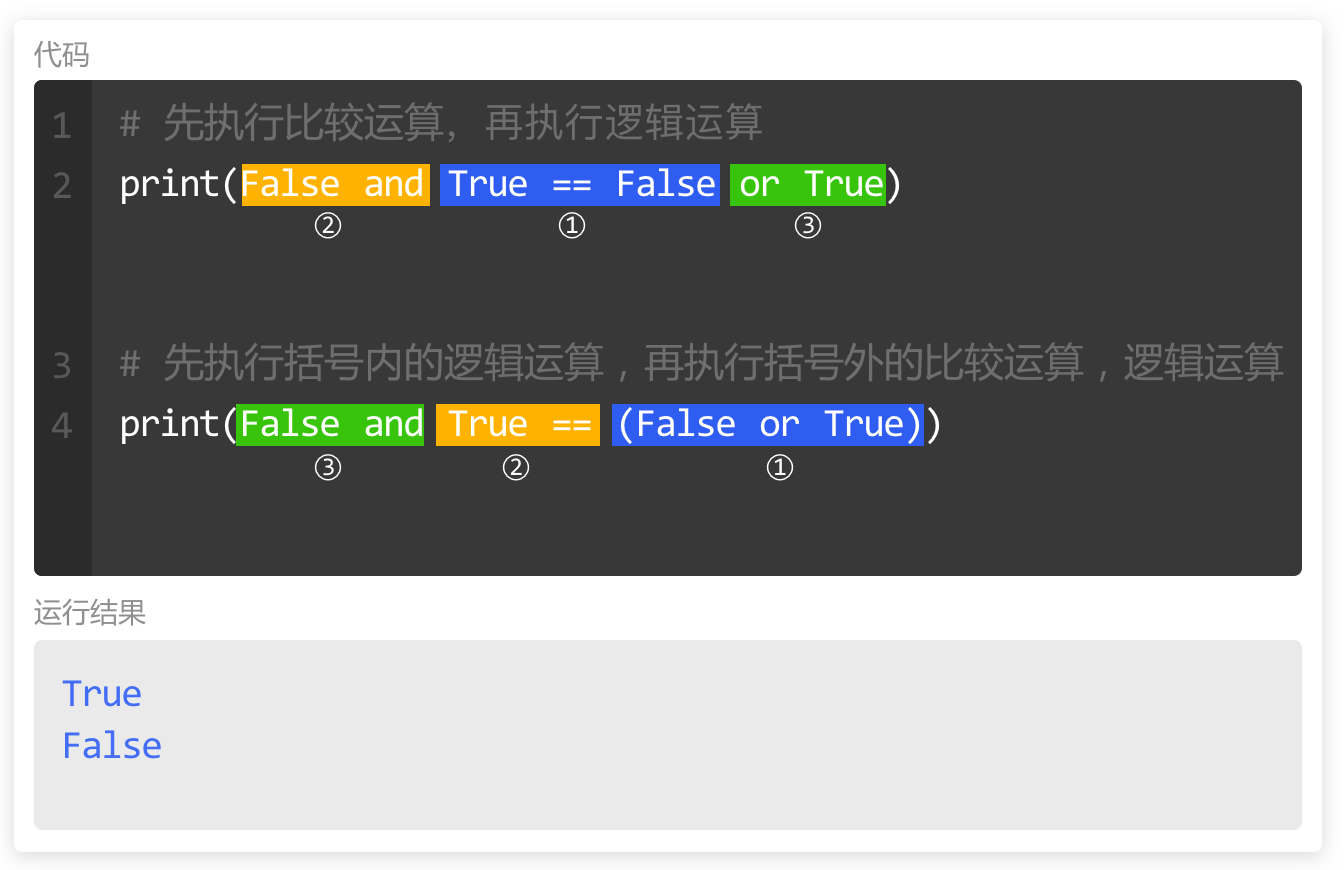
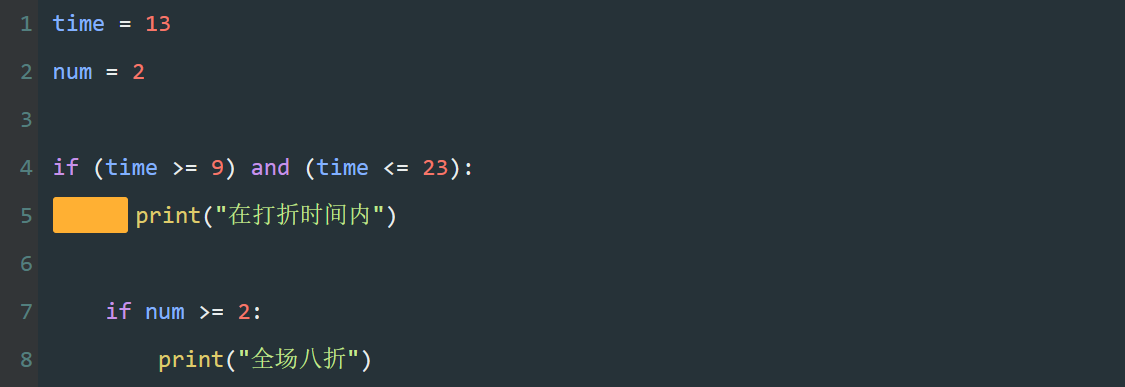
其次,即使括号的使用不影响代码执行的顺序,但也能让代码更加清晰易读,是一种提倡的代码风格。
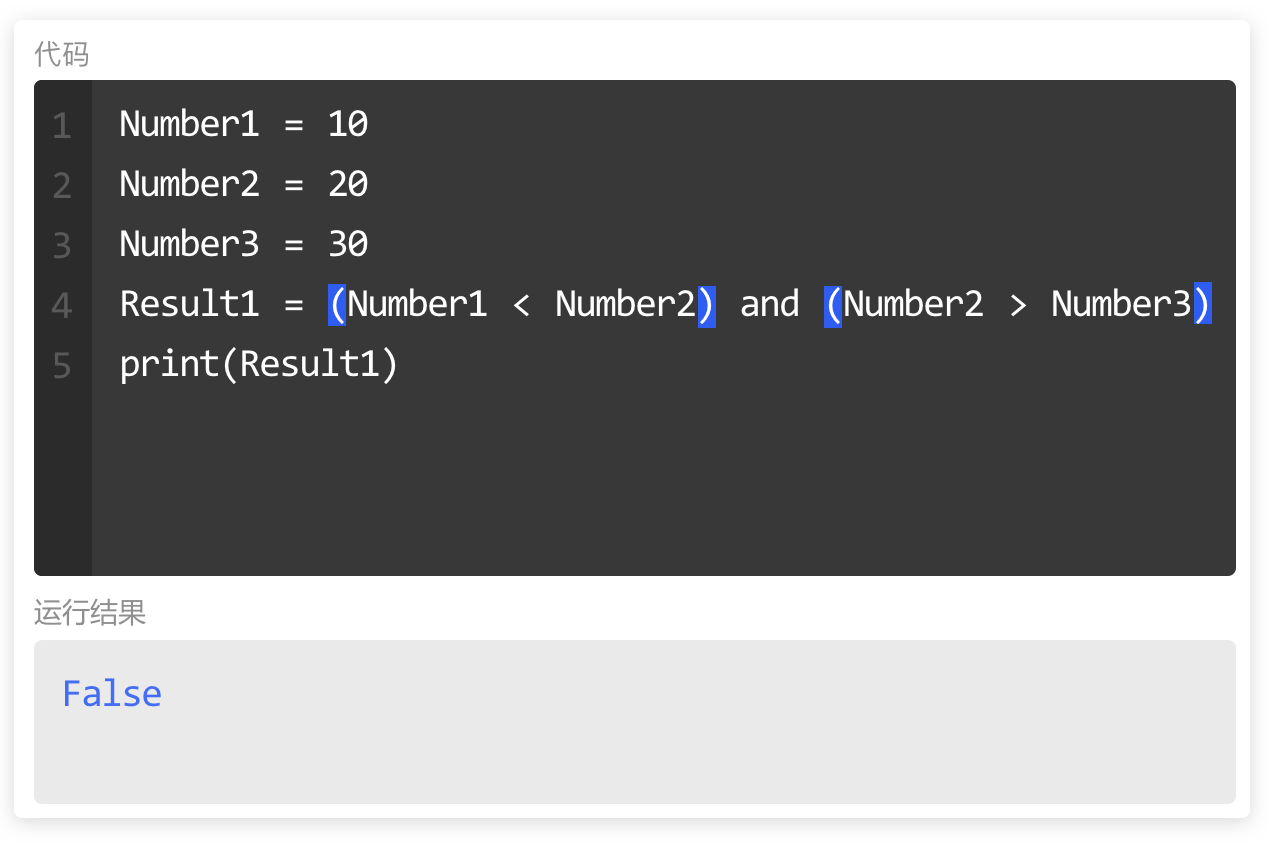
如图,对比较运算使用括号,不影响代码执行顺序,因为Python本身优先执行比较运算。
但在此,让代码更加清晰,更易理解。
刚学习过进行比较运算,和逻辑运算的一串运算式子。
在Python有一个统一的名字——布尔表达式。
布尔表达式
无论是进行简单的比较运算,还是进行了逻辑运算,或者是混合使用。
在Python中,只要运算结果是True或False。这样的运算式,都被统一称为布尔表达式。

以上就是布尔数,6个比较运算符和3个逻辑运算符。
需要对数字的大小进行比较时,使用比较运算符。对布尔数进行逻辑运算时,使用逻辑运算符。